Carrying on from the last blog: https://shermwong.com/2026/02/22/recsys-for-real-time-ai-agents/ – which is a more high level depiction of possible future states of personalized, real-time AI agents. Here we dig into a deeper topic of how backbone transformer models has evolved so far on memory architectures, which is a key module to enable continuous adaptation of agents.
Current State
The way memory extensions are connected to transformer backbones are 3 ways:
- Runtime Memory System: long context enabled KV cache layers + compression
- Retrieval System: aka RAG + retrieval optimizations similar to existing information retrieval tasks (search + ranking + multi-stage + online update)
- Learned Memory State: embedding modules that extended from transformer backbone layers.
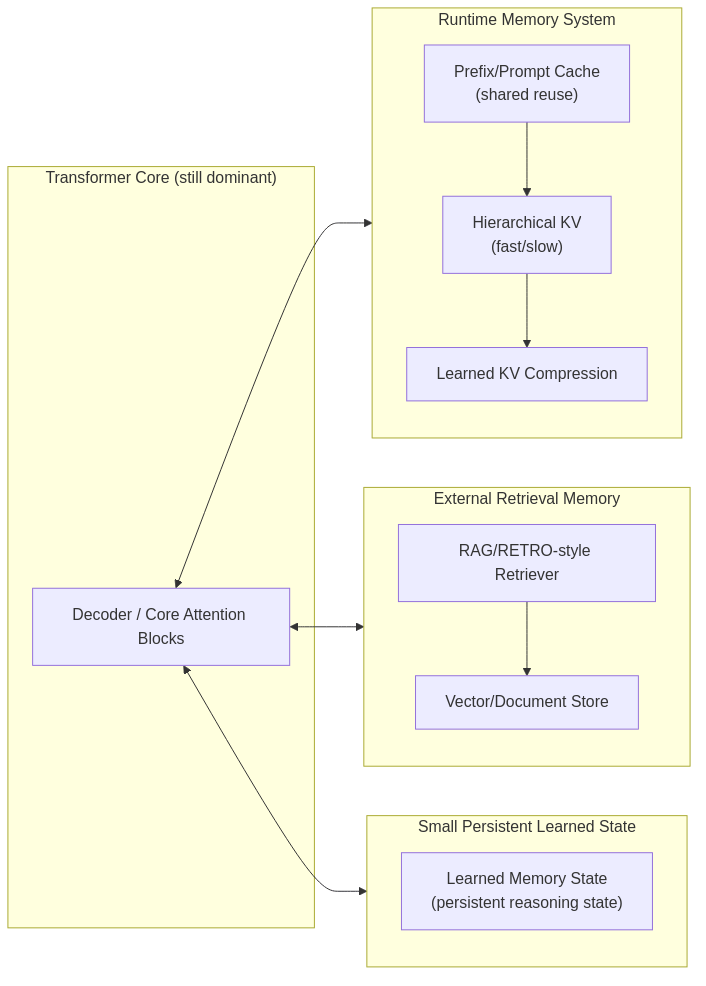
0) Pre-history (foundation)
Transformer-XL / Compressive Transformer / RMT (Recurrent Memory Transformer) Goal: pass hidden state across segments as memory. Limitation: breaks parallelism, unstable at LLM scale.
Core “origin” papers:
- Transformer-XL — Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context (Dai et al., 2019): https://arxiv.org/abs/1901.02860
- Compressive Transformer — Compressive Transformers for Long-Range Sequence Modelling (Rae et al., 2019): https://arxiv.org/abs/1911.05507
- Recurrent Memory Transformer (RMT) — Recurrent Memory Transformer (Bulatov et al., 2022): https://arxiv.org/abs/2207.06881
I) External memory (retrieval memory)
RAG / RETRO / kNN-LM / Memorizing Transformer Idea: memory lives outside the model (vector DB or KV store). Pros: scalable, stable, production-friendly. Cons: not differentiable global reasoning memory.
Adoption: already dominant in real LLM systems.
Origin / high-impact papers:
- RAG — Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Lewis et al., 2020): https://arxiv.org/abs/2005.11401
- RETRO — Improving language models by retrieving from trillions of tokens (Borgeaud et al., 2021): https://arxiv.org/abs/2112.04426
- kNN-LM (NN-LM) — Generalization through Memorization: Nearest Neighbor Language Models (Khandelwal et al., 2019): https://arxiv.org/abs/1911.00172
- Memorizing Transformers — Memorizing Transformers (Wu et al., 2022): https://arxiv.org/abs/2203.08913
- (Common “retrieval-augmented LM line” at Meta) ATLAS — Atlas: Few-shot Learning with Retrieval Augmented Language Models (Izacard et al., 2022): https://arxiv.org/abs/2208.03299
II) KV-cache + structured runtime memory (systems path)
PagedAttention / block KV / shared/persistent KV / compressed KV New direction (2024–2026):
- KV reuse across sessions
- hierarchical KV (fast + slow memory)
- learned KV compression
- Trellis-style bounded KV memory
- prefix/prompt persistent memory
Why hot: inference cost dominates. This is infra-aligned with how real LLMs run.
Adoption: already happening (vLLM, etc.).
Prediction: KV cache will evolve into learned structured memory. This is a practical near-term direction.
Origin / high-impact papers:
- PagedAttention / vLLM — Efficient Memory Management for Large Language Model Serving with PagedAttention (Kwon et al., 2023): https://arxiv.org/abs/2309.06180
- Multi-Query Attention (decoding-side KV reduction primitive) — Fast Transformer Decoding: One Write-Head is All You Need (Shazeer, 2019): https://arxiv.org/abs/1911.02150
- “Trellis-style bounded KV memory” — Trellis: Learning to Compress Key-Value Memory in Attention Models (2025): https://arxiv.org/abs/2512.23852
III) Learned internal memory modules (DeepSeek line)
A) Memory token / slot memory
Examples: memory tokens / prefix memory; Perceiver latent memory. Idea: fixed learnable memory slots persist across sequence.
Problems:
- scaling unclear
- capacity fixed
- retrieval soft/implicit
- weak for precise reasoning
Adoption: low.
Origin / high-impact papers:
- Perceiver — Perceiver: General Perception with Iterative Attention (Jaegle et al., 2021): https://arxiv.org/abs/2103.03206
- Perceiver IO (structured IO via latent bottleneck) — Perceiver IO: A General Architecture for Structured Inputs & Outputs (Jaegle et al., 2021): https://arxiv.org/abs/2107.14795
- Prefix memory framing (continuous prefix as persistent “soft state”) — Prefix-Tuning (Li & Liang, 2021): https://arxiv.org/abs/2101.00190
B) Recurrent persistent memory (RMT lineage)
Examples: Recurrent Memory Transformer; associative memory transformer; LM2 large memory model. Idea: persistent hidden memory updated per segment.
Pros:
- true long-term memory
- infinite context theoretically
- reasoning continuity
Cons:
- kills parallel training
- gradient instability
- hard to scale >100B
- infra mismatch with GPUs
Adoption: research only.
Origin / high-impact papers:
- RMT — Recurrent Memory Transformer (Bulatov et al., 2022): https://arxiv.org/abs/2207.06881
- “1M tokens with recurrence” — Scaling Transformer to 1M tokens and beyond with RMT (Bulatov et al., 2023): https://arxiv.org/abs/2304.11062
- LM2 (explicit “large memory model” framing) — LM2: Large Memory Models (2025): https://arxiv.org/abs/2502.06049
- Associative recurrent memory transformer — Associative Recurrent Memory Transformer (2024): https://arxiv.org/abs/2407.04841
C) Hierarchical / compressive memory
Examples: HMT; Infini-attention; compressive KV memory models. Idea: compress history into structured memory blocks.
Pros:
- bounded memory: no unbounded KV-cache; must summarize / distill / select what to retain.
- closer to brain-like hierarchy
Cons:
- compression loss
- training complexity
Adoption: emerging but not dominant.
Origin / high-impact papers:
- Compressive Transformer — Compressive Transformers for Long-Range Sequence Modelling (Rae et al., 2019): https://arxiv.org/abs/1911.05507
- Infini-attention — Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention (2024): https://arxiv.org/abs/2404.07143
- HMT — HMT: Hierarchical Memory Transformer for Efficient Long Context Language Processing (2024): https://arxiv.org/abs/2405.06067
What changed after DeepSeek
DeepSeek basically signaled: memory will become a first-class architecture primitive. Shift observed:
- Before 2024: focus = longer context
- After DeepSeek: focus = persistent memory + bounded compute
Alpha Paper: Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models (https://arxiv.org/html/2601.07372v1)
New papers now assume: context window scaling alone is not enough.
Why memory transformers still not dominant
- Scaling law economics: increasing context from 128k → 1M is easier than redesigning architecture.
- Parallel training constraint: persistent memory introduces recurrence → bad for GPU throughput.
- Stability: memory update rules destabilize trillion-token training.
- Infra lock-in: everything is built around stateless transformer + KV cache; changing this is extremely expensive.
Convergence path (plausible trajectory, no single bet)
Short term (2025-2026)
Likely evolution: Transformer + production KV-cache improvements + retrieval augmentation.
- KV cache becomes more systemized (paging / sharing / reuse) and begins to look like a runtime memory layer.
- RAG remains the dominant mechanism for adding/updating external knowledge without retraining.
Mid term (2027-2029)
Likely evolution: Transformer + hierarchical KV memory + learned compression + limited/safe parameter updates.
- Hierarchical KV: multiple tiers (fast recent-context + slower persistent tiers).
- Learned compression: distill long context into compact state that can be carried forward.
- Partial sparse updates: update only a small, well-isolated subset of parameters/state (vs. global dense finetuning).
Long term (5–10+ yrs)
One plausible direction (RecSys-inspired, but not guaranteed): a mostly-stable dense backbone plus massive sparse memory tables that support continual + personalized updates.
- Dense core stays largely frozen for stability and compatibility.
- Sparse memory tables (user / task / knowledge) carry most of the continually-updated, personalized signal.
- Updates are sparse/localized (RecSys-style): only a tiny subset of the memory is touched per step.
Why this is only a possibility (not a claim about the future)
- It requires a good answer to what should live in sparse memory for language tasks (and how it is addressed/read/written).
- It requires safe online update rules that don’t destabilize the base model or create rapid distribution drift.
- It requires clean integration with runtime memory (KV/hierarchical KV) and retrieval memory (RAG).
