LLMs need a RecSys layer to truly understand users
LLMs are powerful general reasoning engines, but they are not optimized to model long-term user preference evolution. Traditional RecSys systems solved this decades ago by learning persistent user representations from interaction timelines. The key idea is simple: treat a user’s history as a structured signal, not as raw text. Instead of stuffing entire trajectories into prompts, we compress them into learned embeddings that encode behavior, intent, and preference over time. This shifts personalization from prompt engineering to representation learning.
Agent trajectories are a new form of user behavior data
In an AI-agent world, the core signal is no longer “user clicked item,” but “user ↔ agent trajectory.” These trajectories include user requests, agent tool actions, outcomes, and follow-ups. Many parts of these events already exist as natural IDs (repo, tool, domain, error type, timestamp). Others—free-form text, code, or images—can be converted into dense content embeddings using pretrained encoders. Together, they form a structured timeline of events that can be modeled exactly like a RecSys sequence, but for agent behavior rather than shopping or media consumption.
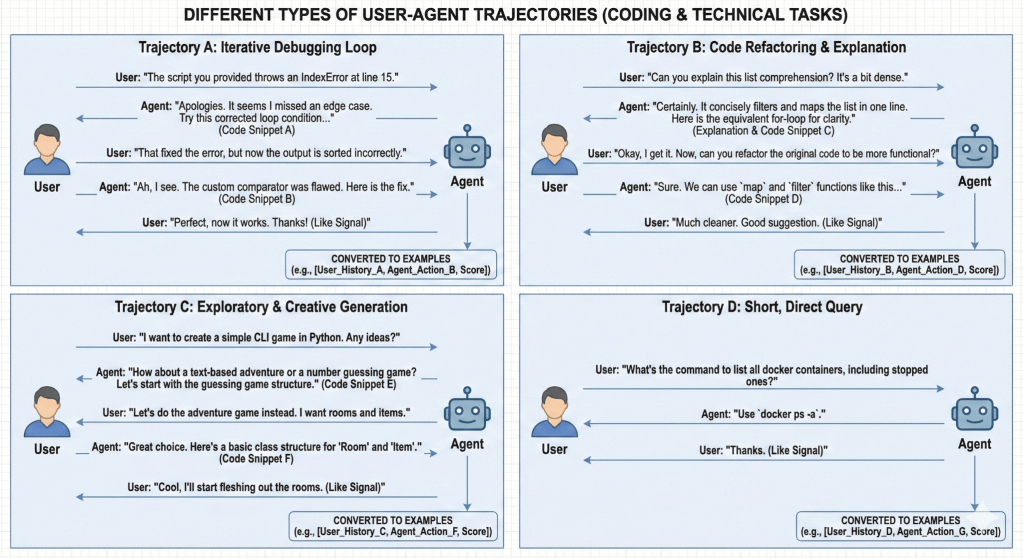
Figure. 1 – Future of Ubiquitous User-Agent Trajectories
The central design choice is to convert agent interaction histories into stable machine-learnable representations. Structured signals (tools, domains, entities, timestamps) become sparse IDs stored in embedding tables. Unstructured signals (text queries, responses, code, images) are mapped through pretrained encoders into dense vectors. This hybrid representation allows the system to scale like classical RecSys—efficient lookup and updates—while retaining semantic richness from modern foundation models. The result is a unified representation of user behavior across structured and unstructured modalities.
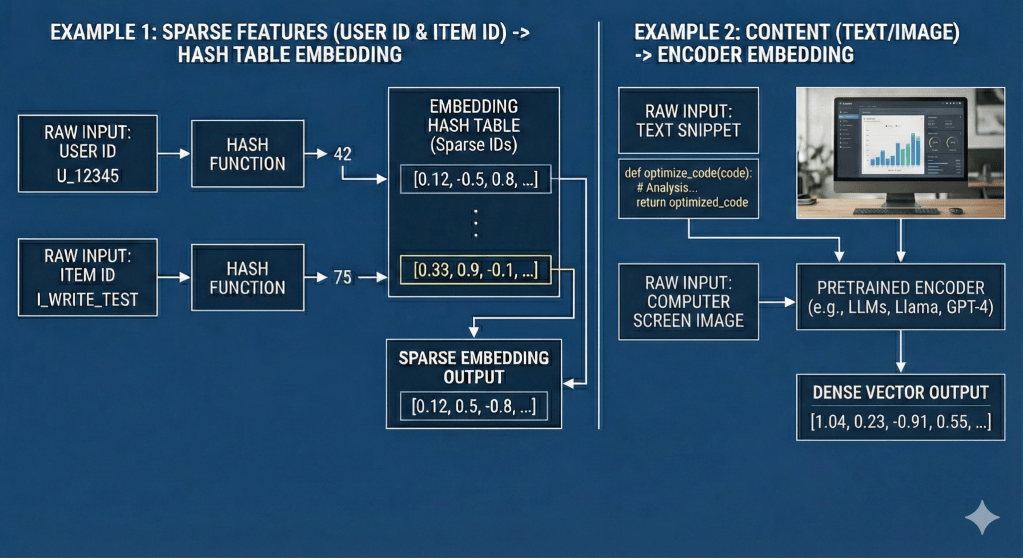
Figure 2 – Convert Trajectories to Sparse IDs
Interaction modeling becomes the core intelligence
Once user histories and current queries are embedded, the system must model how they interact. This is where RecSys techniques shine. Efficient interaction layers—factorization-style or cross-feature networks—capture how a user’s long-term preferences interact with the current query or task. For example, a user who repeatedly asks for refactoring help and prefers concise code fixes should receive different agent actions than one who prefers detailed explanations. These higher-order interactions are difficult for a generic LLM to learn implicitly, but become tractable when modeled explicitly in a RecSys-like architecture.
Learning signals come from both behavior and simulation
Unlike classical RecSys, agent systems can generate their own training data. Learning can combine three signals:
- LLM synthesized interaction rollouts generated by agent and “simulated users”
- Explicit real user feedback (likes, corrections, accept/reject actions).
This mixture dramatically improves sample efficiency and allows the model to learn continuously as users interact with agents in real time.
The New paradigm: RecSys for real-time AI agents
The resulting architecture resembles a RecSys system fused with an LLM stack: a persistent user-preference model feeding real-time contextual signals into an agent. Instead of treating every conversation as stateless, the system maintains a continuously evolving representation of each user. This enables true personalization at inference time: the agent does not just respond to the current prompt, but to the accumulated behavioral history of the user.
In effect, personalization for AI agents becomes a recommendation problem—except the “items” are actions, responses, and decisions.
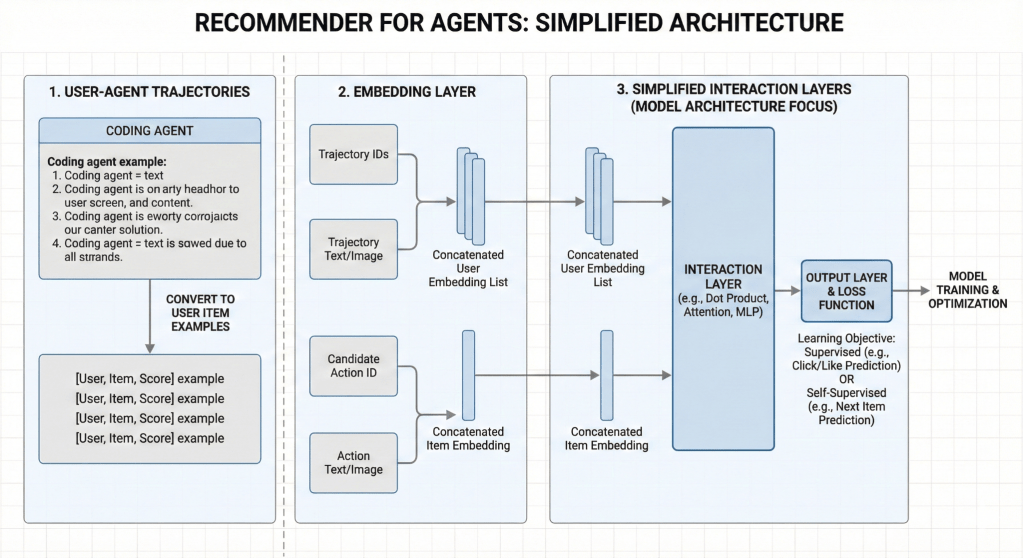
Figure 3 – Agent Recommender – Model Architecture
How Continual Learning is Naturally Enabled
User preferences naturally drift over time as their corresponding embeddings are updated with each interaction. Since each user’s embedding space is independent, there is no catastrophic forgetting of other users’ preferences.
Related Works
There are 3 mainstream works that are targeting similar problems:
- LLM continual learning
- LLM-based RecSys models
- Learned memory blocks for LLMs
| Approach | Update Mechanism | Scalability | Continual Learning | Personalization |
|---|---|---|---|---|
| USER-LLM [1] | Dense two stages (encoder pretrain + encoder-LLM finetune) | Low | No | Medium |
| Self-Distillation [2] | Full Model Fine-tuning | N/A | Yes | No |
| DeepSeek Engram [3] | Static Memory Table | N/A | No | No |
None of the current LLM approaches leverage the core RecSys insight: treat users as sparse features and only update their corresponding parameters.
References
[1] Liu, L., & Ning, L. (2024). USER-LLM: Efficient LLM Contextualization with User Embeddings. Google Research Blog.
[2] Shenfeld, I., et al. (2026). Self-Distillation Enables Continual Learning. arXiv:2601.19897.
[3] Cheng, X., et al. (2026). Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models. arXiv:2601.07372.

One thought on “RecSys for Real-time AI Agents”