The Basics
Post-training – Scaling Test Time Compute
The biggest innovation from GPT-o1 is that it proves test time scaling is another dimension besides scaling data and model parameters.
Both RL and best-of-n therefore share a common structure, differing only in when the optimization is paid—RL pays the cost during training, best-of-n pays it during inference.
GPT-o1 made this explicit: its performance increases smoothly with additional inference-time “thinking tokens” or trajectory search, even without changing weights. DeepSeek-R1 and other 2025 reasoning models extend the same idea—longer reasoning traces, larger candidate sets, and more verifier compute directly raise accuracy.
One question is how does RL post-training expand the capability boundary of pre-training – this NeuralIPS best paper argues otherwise: Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model uses pass@k curves on reasoning tasks to show that current reinforcement learning with verifiable rewards (RLVR) does not actually teach large language models new reasoning abilities — it mainly improves sampling efficiency, while the underlying reasoning capacity already exists in the base model.
Pre-mid-post train Interplay
How is thinking/reasoning behavior actually bootstrapped? We need to revisit into pre-training and mid-training stages.
On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models
Mid-training is considered to be an extended coldstart SFT stage to bootstrap reasoning – to enable LLMs to generate high quality thinking trace, quantity and diversity of training dataset also matters. From an evaluation standpoint, mid-training essentially transitions from optimizing NLL targets to optimizing downstream SFT+RL metrics.
Mid-training significantly enhances performance under fixed compute budget compared with no-mid-training (pre-train → post-train). Recent work has noted that models like Qwen respond far more effectively to RL than architectures such as LLaMA. A converging explanation is the presence of a mid-training stage that aligns supervision more closely with the post-training distribution.
Reasoning-oriented mid-training has been shown to substantially increase a model’s RL readiness. Essentially the training pipeline is designed to treating mid-training as the phase for installing priors and RL as the phase for scaling exploration
RLVR – Motivations
What are Verifiable Rewards? Verifiable rewards are objective, programmatically checkable signals (usually binary correct/incorrect) that indicate if an LLM’s output meets a ground-truth criterion (labelstud.io). In practice, these rewards are derived from tasks with known answers or rigorous checks – for example, solving a math problem or passing unit tests for generated code.
Why are verifiable rewards considered scalable? Since the feedback is generated by deterministic checks (e.g. exact match with a solution or executing code), the process minimizes reliance on human judgment and manual labeling. Empirically, models trained with verifiable rewards have shown remarkable improvements on reasoning benchmarks as data and compute are scaled up. For instance, one pure-RL approach (DeepSeek-R1-Zero) learned complex problem-solving from scratch, boosting its math exam accuracy from only ~15.6% to over 71% after thousands of RL steps (and up to 86.7% with ensemble voting). Notably, this was achieved without any supervised fine-tuning, demonstrating that an LLM can “self-evolve” reasoning skills purely via large-scale RL on verifiable tasks.
Where are RLVR training applied? Common domains used to provide verifiable rewards include mathematics (numeric problem solving with known solutions), coding (where unit tests or execution results give a binary pass/fail), formal logic puzzles, and constrained instruction-following tasks (produce answers in a prescribed format).
SFT vs RLVR
In practice RL training is much less efficient than SFT due to 10x higher rollout cost (generation cost). so a (sometimes very heavy) coldstart SFT process is still necessary before RL, while RL only applies a small set of tasks (input prompts), e.g. for some coding tasks only a few thousand tasks. Below is a demonstration of the multi-stage pipeline:

Public SFT dataset for reasoning:
| SFT Dataset | Source/Origin | Volume (Examples) | Eval Dataset/Metrics |
| Open Thoughts v1 | Open community | 100k | MATH-500, pass@1 accuracy |
| AceReasoner 1.1 | NVIDIA | 100k | MATH-500, pass@1 accuracy |
| Open R1 Math | DeepSeek R1 | 10k | MATH-500, pass@1 accuracy |
| Open o1 | Community | 10k | MATH-500, pass@1 accuracy |
| LIMO | DeepSeek R1 | 1k | MATH-500, pass@1 accuracy |
As of 2025, DeepSeek’s CoT traces (as used in LIMO) are considered superior to other models’ traces for reasoning tasks
Note of Reasoning-based SFT:
- Scaling up data quantity and diversity always brings consistent gains in reasoning capabilities
- Diversity is not just in topics, but in reasoning strategies and problem complexity.
- High SFT scores can be misleading, especially when achieved by overfitting on small or homogeneous datasets. These models may perform well on SFT metrics but fail to generalize, resulting in poor RL performance.
- Diversity vs. Homogeneity:
- Homogeneous Data: Fast SFT gains, poor RL transfer.
- Diverse Data: Slower SFT gains, better RL transfer.
- Diversity vs. Homogeneity:
RLHF vs RLVR
Can RLVR replace RLHF? NOT exactly, RLHF is still needed for AI “alignment tasks”, including helpfulness/harmless, e.g. stuff like DPO can be used as “hot-fix” to patch the model using online preference pairs.
Mixed-stage RL Training: the trend is moving towards a mixed training pipeline between RLHF (reward model) and RLVR
- Dataset can be mixed, evident in Qwen 3 Tech Report, GLM-4.5 has a similar pipeline
- Model can be trained simultaneously on alignment, reasoning and instruction following to improve generalization, as long as a mixed stage RL training infra is able to load multiple reward models and multiple scorers.
- Ideally, SWE-agent like complex rollout (async, multi-step interaction with environments) can also be mixed this way, but no literature has shown this yet, possible due to the highly complex infra setup.
- Question: is instruction-following supposed to be in pre-mid-training or in RVLR?
- IF is a multi-dimensional concept, all these stages need to join together to improve IF
Scaling RLVR – Dimensions
Scaling Training Data
Scaling Problem Domains
Grok 4 expanded verifiable training data from primarily math and coding data to many more domains (science, real-world tasks, safety-relevant areas), with more internally generated/synthetic data in the mix.
DeepSeek V3.2 encompasses six specialized domains: mathematics, programming, general logical reasoning, general agentic tasks, agentic coding, and agentic search, with all domains supporting both thinking and non-thinking modes. Additionally, DeepSeek builds a large-scale synthetic agentic task dataset with: ~1,800 distinct environments and ~85,000 complex agentic prompts, designed to integrate reasoning with tool use (e.g., search and coding tools) as part of the reinforcement learning steps.
For RLVR, there are limited high quality input tasks (prompt dataset) available, especially for training dataset like SWE-agent (the size typically at the scale of 1-2k tasks). Curating good reasoning problems + verifiers is a difficult task, we believe RL performance is still bottlenecked on high quality agentic, verifiable tasks available for training.
Scaling Compute
Besides quantity and diversity of problems, reasoning performance is obtained from specific training dynamics instead of raw dataset size, we have summarized a few scaling dimensions that are worth noting.
Batch size (larger batch):
- The number of PPO steps also matters (from 100 to up to 2000 steps!)
- Length/advantage normalization
- Async RL for off-policyness (VeRL), initialization from mid-trained + SFT checkpoint.
- Sometimes mysteriously smaller batch size is better.
Effective Batch Size Impact: A critical benefit is increased effective batch size – the number of problems with both passed and failed solutions
- Effective PPO batch size, related to global batch size, dynamic sampling strategies (zero-adv-filtering etc.), and num of generations per prompt.
Context Length Scaling:
- Phased training (8K → 16K → 24K tokens).
Curriculum Learning/Dynamic Sampling
Dynamic sampling was first introduced in the DAPO paper — essentially, if all outputs of a particular prompt are correct or incorrect (and hence receive the same reward), the resulting advantage for this group is zero which results in zero policy gradients, which decreases the sample efficiency of overall training and increases sensitivity to noise. The authors propose dynamic sampling – by oversampling prompts and filtering out those with the accuracy equal to 0 or 1 – to create a batch with non zero advantage values. The idea can be further extended to adjust the “difficulty” of rollout, altering the sampling rate of prompts based on “difficulty” to let the model focuses on “hard but solvable” problems, e.g. those with intermediate pass rates—e on very easy (23% of problems, 80%+ pass rate) or impossible (44%, 0% pass rate) tasks
The idea of dynamic-sampling is more closely related to the idea of curriculum learning, where the training loop can be altered to train the model on different data distributions.
Synthetic Prompts: why is it important:
- Coverage and token budget: Synthetic prompts let the system cover more domains and reach large token budgets of reasoning traces without duplication—crucial for training stability and variety that helps RL.
- Better initialization for RL: Stronger base from mid-training (fed by synthetic prompts) helps the RL loop achieve better final accuracy ceilings.
For Math and Code Domain, a large amount (to millions) of prompts can be generated using few-show examples. A notable work is Kimi 2 , They adopt K1.5 and other in-house domain-specialized expert models to generate candidate responses for various tasks, followed by LLMs or human-based judges to perform automated quality evaluation and filtering.
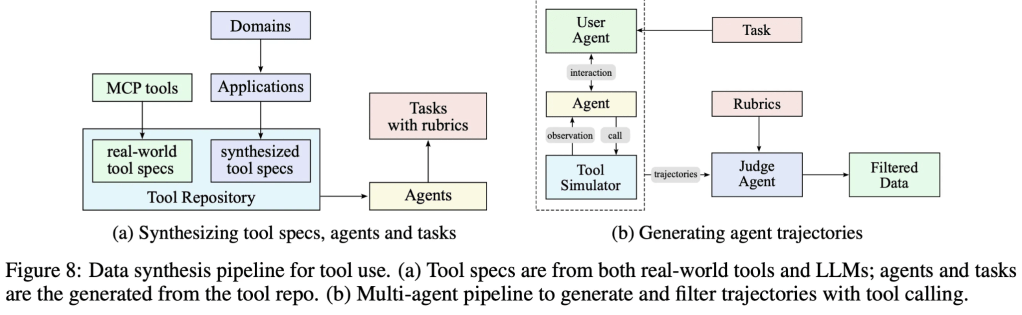
Rejection sampling vs synthetic prompt
- Synthetic prompts are used to scale up training, teach diversity, and bootstrap models when real data is limited.
- Rejection sampling ensures high-quality, correct data for supervised fine-tuning (SFT) and RL, but is bottlenecked by the need for verifiable prompts.
Synthetic prompts are increasingly favored for mid-training and cold-start SFT, while rejection sampling is used for high-quality, correctness-focused data, especially in RL phases. The current trend is shifting from pure few shot generation to real E2E agentic trajectories, see a recent work and Code-World-Model. We will dive into this E2E picture in the next RL Environment section.
Scaling RL Environments
The Code-World-Model is built upon 2 types of environments:
- Python Traces:
- Over 30,000 executable repository Docker images sourced from public codebases
- The Docker images contain a full environment (dependencies, tests, build scripts), allowing code to be run reproducibly to capture program state (e.g., stack frames and variable contents) before/after each executed line
- Agentic interaction data:
- Tasks are mined from real-world issues, pull requests, and test failures in these open-source projects
- 3 million trajectories collected
SWE-gym contains ~2,438 real Python task instances with runnable environments and tests. They fine-tune Qwen‑2.5‑Coder‑Instruct‑32B using 491 successful SWE-Gym agent trajectories (≈19k tokens, ~19 turns each) via rejection-sampling fine-tuning on the OpenHands scaffold, and evaluate on SWE‑Bench Verified. This improves resolution rate from 7.0% → 20.6%, and with a verifier trained on 2,636 trajectories, inference-time Best@16 further rises to 32.0%
As of 2025, high quality envs are very very limited, most likely proprietary envs are built in-house by frontier labs like OAI or Anthropics.
Scaling Verifiers
Non-verifiable domains
Expanding RL with Verifiable Rewards Across Diverse Domains trains a Qwen2.5-7B policy with RLVR and shows that replacing “binary verification” with a learned, soft verifier: the verifier (a 7B reward model) is distilled from Qwen2.5-72B-Instruct judgments on ~160k generated responses and outputs a continuous score in ([0,1]) instead of a hard 0/1. Evaluated on free-form multi-domain QA (medicine, chemistry, psychology, economics, education; ~6k questions) and math reasoning, RL with dense rewards reaches 31.2% avg accuracy on multi-domain tasks vs 23.1% (SFT), and 63.0 on math vs 58.5 with binary rule-based RL, with gains widening as RL data scales.
Rubrics
A mixture-of-judge rubrics are applied during RLVR training, the rubrics can be hand crafted or generated based on a human-in-the-loop process to identify “verifiable sources”.
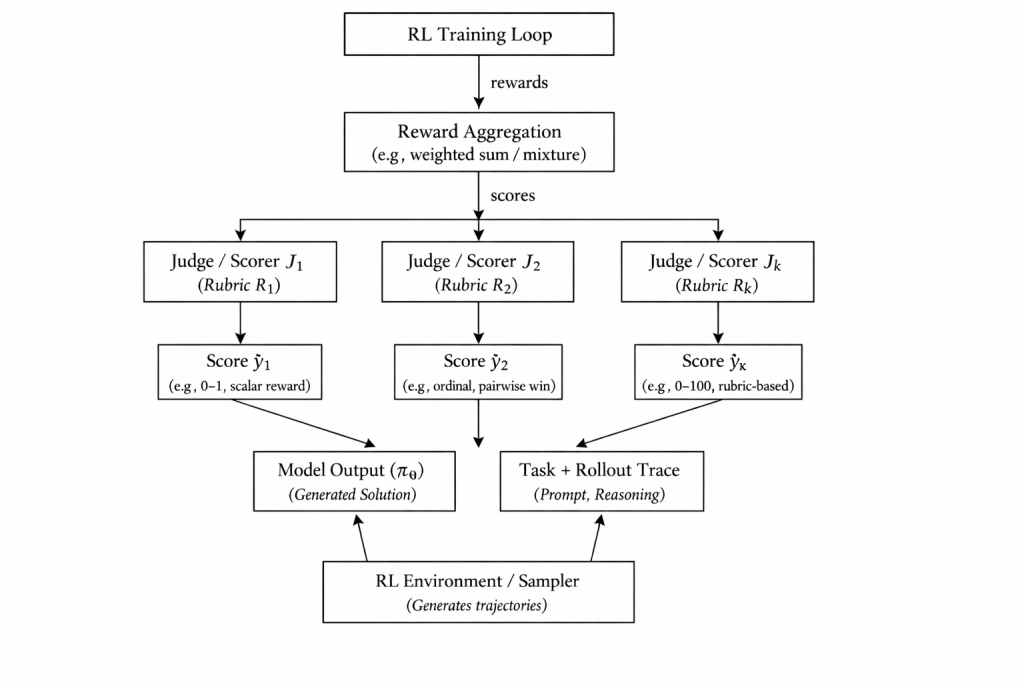
Using handcrafted rubrics is a tedious process; a research topic is how to train generative LLM judge models that are robust to reward hacking. If the judge model is misaligned or shortsighted in some way, the primary model will optimize toward a possibly flawed target. For example, models have learned to output things that “look good” to an AI grader but are actually factually wrong or deceptive. Continuous oversight or periodic calibration with humans may still be needed to ensure the AI feedback doesn’t drift from true usefulness. In truly subjective arenas there’s no single gold standard. This makes benchmarking and progress evaluation trickier: improvements under one AI judge might not translate to another, or to humans. In summary, non-verifiable reward approaches offer a path to scale alignment across many complex tasks, but they require careful rubrics design
How does RLVR enable reasoning models?
Let’s breakdown reasoning into multiple phases:
[Phase 1] coding & math reasoning
Generic reasoning: typically evaluated by:
- Increased thinking-length
- Thinking patterns
What are the examples? Imagine your are solving a math & competitive coding problems, here are the thinking strategies you’d typically apply:
1. Input Analysis & Constraint Extraction
Parse input variables and constraints.
Identify key parameters and their bounds.
2. Data Structure Selection
Choose efficient data structures for mapping relationships.
3. Greedy/Optimal Assignment
Assign values based on optimality (max/min, closest, etc.).
4. Edge Case Handling
Explicitly check for and handle edge cases.
Domain reasoning: learned thinking patterns of specific problem space
How is it different from memorization then?
- It’s complicated, for example, imagine you are solving the agentic coding problems, there are some good strategies you should memorize while interacting with the bash environment, e.g:
- Use grep + view lines to efficiently navigate a large code file
- Use test-driven development to write a self-contained test script to reproduce the issue before starting coding.
- These domain specific thinking strategies are more efficient to learn thru memorization than exploring a large amount of tasks/trials., yet the current RL paradigm still learns thru “trial-and-err”.
Tool-learning has been a good proxy paradigm to adapt agent to domain tasks, essentially, agents are trained with outcome-reward RL to teach LLMs when/how to invoke external tools.
- ToRL uses GRPO on 28 k math contests + a Python sandbox, thru RL training they have observed agent demonstrating strategic tool invocation, self-regulation of ineffective code generation, and dynamic adaptation between computational and analytical reasoning.
- ARTIST uses GRPO with answer + format + tool-success rewards; it also generalizes the math-only setting to mixed tasks (20 k math + ≈100 multi-turn BFCL calls). Its interleave think/tool/output is very similar to Confucius’s CCA’s tool-use based reasoning design.
- Tool-N1 (Nemotron-N1) uses GRPO on ToolACE + xLAM in total of 5518 traces + a binary “Tool Call Correctness” reward with ground-truth annotations.
Bootstrap Thinking
- Thru iterative cold-start → RL:
SFT –> RLVR → rejection sampling → SFT → RL
- Through distillation from large teacher models: directly learn thinking trace logits from large teacher models, on-policy-distillation has been proved effective in this route.
Where is the saturation point? As of 2025, it is evident that “simple” reasoning benchmarks like AIME 2025 and swe-bench-verified already saturated, frontier labs are shifting towards real-world, long horizon reasoning tasks, and apparently scaling thinking continue to improve such tasks, one prominent benchmark is SWE-bench-pro performance (a much harder and production-oriented set), see https://arxiv.org/abs/2512.10398 on SOTA performance achieved thru high thinking models. Similar difficult benchmarks are SWE-perf, SWE-efficiency and AlgoTune
[Phase 2] Long horizon, long step reasoning
DeepSeek V3.2 has formally proposed recipes for such tasks, typical use cases include deep research and agentic coding (swe-bench-pro)
It is questionable that if scaling thinking along is sufficient, model size seem still matters:
- The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs shows that long-horizon failures often stem from execution errors (compounding per-step inaccuracies and a self-conditioning effect) rather than lack of reasoning or planning, and that scaling model size (Gemma-3: 4B, 12B, 27B and Qwen-3: 4B, 8B, 14B, 32B) non-diminishingly improves execution on long chains of simple steps when the reasoning/planning is given.
- Definition of execution errors: mistakes made while carrying out a known, correct plan with provided knowledge
- The “self-conditioning” effect: imagine the following agent execution traces:
1. Happy path: action → result → action → result
2. Self-fixing: action → failed → action → result
- Ideally we want agents to be able to adapt to both 1 and 2 scenarios, while “self-conditioning” occurs when the agent starts to collapse in scenario 2. Such an effect is much more subtle and cannot be properly evaluated with an agentless evaluation dataset (Q&A only); it can only be observed in a full E2E agentic environment (or interactive chat sessions).
No public coldstart data for long horizon reasoning; and it is questionable that SFT alone can learn long horizon tool use and exploratory behaviors (usually involves bash environment interactions, computer use). RL still proves to be essential to achieve long horizon reasoning capabilities.
Kimi-Researcher is a good example adopting E2E RL training to tackle long horizon reasoning, its training strategies includes:
- On-policy training and outcome-based rewards.
- Negative sample control: Improves learning efficiency and model performance by controlling negative samples during training.
- Automated data synthesis: Addresses data scarcity through methods that automatically generate high-quality training data.
- Context management: Implements an efficient mechanism to manage the agent’s contextual information in long-horizon tasks.
- Fully asynchronous rollout system: Significantly boosts data throughput and training efficiency by generating interaction data through a fully asynchronous rollout system.
After end-to-end RL training, Kimi-Researcher exhibits advanced capabilities beyond basic instruction following, such as resolving conflicting information from multiple sources, demonstrating the potential of end-to-end agentic RL
[Phase 3] Self evolving & self learning
In this phase, the agent should be a lot more proactive on improving and update itself instead of relying hand-crafted tool & prompt designs , we will see how this direction evolves in the next 2 years as frontier labs continue to drive agent capabilities thru RL, notable directions include agentic memory (long term memory), and AlphaEvolve
AlphaEvolve is an agent to discover new algorithms in coding. Think of it as a really specialized agent digging really deep into a task, running 24/7 to find a solution. AlphaEvolve is particularly powerful when tackling mathematical algorithms which requires large search space to discover optimal solutions
The agent doesn’t rely solely on a fixed, human-written prompt – it allows the LLM to suggest improvements or additions to the prompt in order to guide its own future behavior
Imagine AlphaEvolve is trying to evolve an algorithm for a tricky optimization problem. Initially, the prompt to the LLM might just describe the problem and say “Improve the code.” Now, with meta-prompting, the system does something clever: it asks the LLM to first come up with an extra hint or strategy to add to the prompt. For example, the LLM might generate a suggestion like: “Hint: consider using symmetry in the problem to reduce complexity.” AlphaEvolve then appends this hint to the actual prompt that it uses for code generation. If the new solutions with this hint score better, the meta-prompt is deemed helpful and retained for future iterations.
Examples
- Discovered a heuristic scheduling algorithms that saves 0.7% compute resources for Google’s data center
- Discovered a new matmul kernel for TPUs with 23% speed-up that resulted in 1% reduction in Gemini’s overall training time
In future such self-evolving agent can be used as “Meta-Agent” (proposed in this work) to self construct and improve agents on its own little prompting or coding needed by human, only a high level goal needs to be specified and a Meta-agent will work 24/7 until a satisfactory solution is found.
The Future
Pre-training Scale RL: In the Grok 4 technical report, xAI reveals that they scaled the RL fine-tuning to pre-training scale, leveraging their 200k-GPU Colossus supercluster (x.a). They also vastly expanded the RL training data beyond the primarily math/coding tasks used for Grok 3, incorporating many domains with verifiable outcomes. The result was a massive RL run that yielded smooth and sustained performance gains throughout training. A slide presented during Grok 4’s launch (see Figure 1) showed Grok’s performance improving steadily as RL compute increased, with no obvious plateau even at the highest compute tested (interconnects.ai). It will be extremely interesting to see other frontier labs follow suit and push this ceiling and unlock more agentic capabilities for downstream applications.
Model Productionization: As RLVR training turns to multi/mix-stage, the training pipeline design/productionization becomes an even more challenging engineering problem. Labs will treat this process with much rigor and design a more sophisticated process for evaluation/quality assurance. New job titles such as “LLM Q&A” or even “Vibe testing QA” will emerge.
Async RL and Offline RL: More sophisticated async RL paradigm, full async RL, or even Offline RL in scenarios where online rollout is expensive or prohibitive.
Scale Environment with World-Model
Although we have talked about Code-World-Model trained thru code execution traces, its training process still resembles a traditional LLM. Here let’s look at the concrete definition of “world-model”:
World-modeling objective = predict the next state given the current state and action.
Implemented via standard autoregressive token prediction:
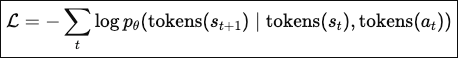
Experience Synthesis is another work that shares a similar spirit.
With the World-model, training teams can simulate environment dynamics and provide unlimited feedback to RLVR training. It’d be interesting to see how this direction shakes out in the next 2 years as the big labs seek more cost-effective way to tackle the sky-high costs of rolling out RLVR environments.
