In the previous post, we articulated the distinction between supervised fine-tuning (SFT) and instruction fine-tuning (IFT). As the field advanced through 2024, the focus shifted to applications. IFT is now widely regarded as alignment research, while SFT serves as a versatile tool to adapt generic LLM checkpoints to specific domains. For practitioners, SFT remains the easiest and most straightforward method to implement.
This post is a quick survey into understanding of scaling and generalization properties of SFT, w/ an easy-to-understanding taxonomy of methods.
LLAMA 2 Era (2023)
In this era, the base model is still weak, post training recipes are not fully discovered. SFT was initially practiced by domain experts to directly train on base (pre-trained) checkpoints to a specific domain data.
Generated programming problems
Solving grade school math problems (GSM8K, MATH)
- Orca-Math
- WizardMath
- On arithmetic tasks
In addition to math and programming, many startups are pursuing fine-tuning on medical and law data; very little progress has been released from these startups.
LLAMA 3 Era (2024)
In this era, SFT became the go-to method for application owners to optimize their own tasks. Research on SFT are not as active as LLAMA2 era due to a few reasons:
- Application owners are private companies, not publication focus
- The task formulation (to be materialized into question – response pairs) really depends on the specific objective, there is no silver bullet
- Fine-tune for generic reasoning is essentially a disproved direction as O1/DeepSeek rocking the boat with RL tuning (will have a separate post addressing these)
A few outstanding works worth mentioning:
Instruction priorities – what if the instructions tuned are conflicting to each other?
Scaling law on SFT
- Alibaba’s study
- Experiment is done on LLAMA2, observed log-linear scaling of scores w.r.t SFT examples on GSM8k; see below, mixed means mixing GSM8k data with other domains.

Discussion
It’s generally believed that the model will continue improving as long as more supervision is available through SFT, whether it’s log-linear depending on the exact task, i.e. similar scaling is not observed on HumanEval.
This paper also proposed a very good rehearsal mechanism using multi-stage fine-tuning, rehearsal with general SFT data has also been proved to be an effective method to avoid forgetting.
Scaling law of SFT on synthetic examples – most at math & coding domain
- ReST-EM
- Iterative fine-tuning, using a binary reward, observed saturated test set performance when growing # of iterations and non-saturated gains when scaling num of questions (prompts) up to 7000
Discussion
Scaling on synthetic examples is essentially cannibalizing the perf gain of scaling test time compute. Depending on the reward quality, such synthetic approach can go very far (at least proved in Math/Coding domain). Another thing to watch out for is, as such methods are essentially unsupervised, it’s important to experiment on whether scaling number of problems (# of prompts, or prompt diversity) provide consistent win.
Using PEFT to address forgetting
Training to memorize (still a research topic), a few key observations:
- The fragility of parametric knowledge: LLMs have learned basic knowledge of the world during pre-training. However, such parametric knowledge is fragile and leads to hallucination.
- The same argument holds for continuous pre-training (CPT) for SFT purposes.
- Underisable memorize: once it memorize it never forgets
- Lamini Memory-Tuning: training random initialized “experts” to memorize – a very good idea but needs time testament
- Train on unknown encourages hallucination
- Note this still uses PaLM 2 as the base model which appears to be too weak in LLAMA 3 era, so not sure if the conclusion still holds in the next few gen of models.
SFT for generic reasoning (thinking traces)
s1: Simple test-time scaling — 1000 sampled from “topics” classified by a taxonomy focusing on math but also include other sciences such as biology, phsiycs, and economy (check the paper for the 3 criteria applied to sample SFT dataset)
- Again it proved SFT MAY work with so few examples like this
Future?
Given it’s already a sophisticated method, we project future production SFT pipelines to be very dynamic, imagine a data flywheel to quickly iterate on the following cycles
- Define new tasks → new model, new eval set
- Collect/synthesize SFT questions-response pairs from knowledge sources
- Update checkpoints and deploy a new model
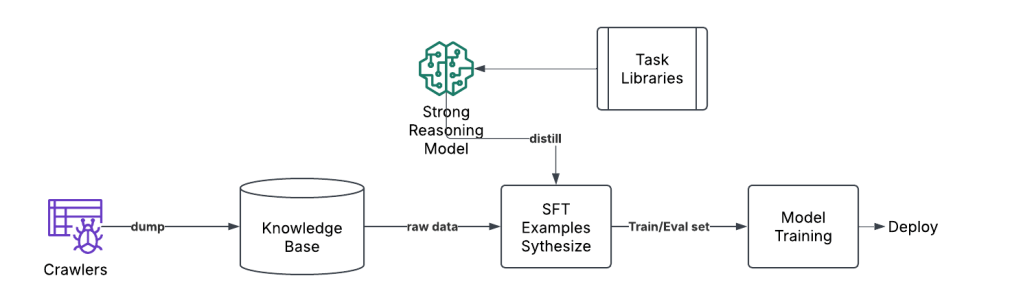
SFT Knowledge Sources
| Knowledge Category | Quantity | Processing Difficulty | Examples |
| structured | small | low | Codebase Textbooks User Manual Documentations |
| unstructured | large | high | Enterprise data Behavior data logs/charts/images/diagrams/screenshots Incident Reports |
This automated process can maintain a “pool” of models that are each optimized for a particular objective and also easy to revert/update.
Open-ended Questions
Q1 – Should I train with pre-trained or post trained checkpoints?
The model acquires strong general problem solving skills during post training, hence training on pretrained checkpoint will lose such abilities. As of 2024, the most efficient recipe is to train on post-trained checkpoints, while using PEFT etc method to address forgetting – only when forgetting hurts the task objective – in fact many tasks are extremely limited in examples (a few hundred) and couldn’t care less about forgetting. Surprisingly SFT CAN work well on so few examples like this.
Alternatively, continual pre-training (CPT) are proposed when large amounts of unsupervised corpus is available.

Intuitively, this introduces more problems than it solves, how do you “recover” the long, messy post-training “surgeries” (still far from automated) after adapting the pre-trained checkpoint? How do you ensure the new knowledge is actually absorbed the “right way”? These problems are nonexistent in LLAMA 2 era (see above categorizations). In LLAMA3 era, post training has become much more complicated, which is usually a multi-stage process involving SFT, DPO, PPO etc.
Hence, so far we haven’t observed successful CPT applications in the industry, SFT is more narrowly scoped to task specific training on “labels”.
Q2 – What if I only have a few hundred examples?
SFT is not a data efficient method, similar to behavior cloning, one should not expect magics – that model can generalize to strong problem solving skills with few data available, (say a few hundred), especially when the domain is full of acronyms, unfamiliar concepts (to the pretrained LLM), not-self-contained examples (large amount of context to absorb) and fast refreshing contents.
Q3 – how to trade off R.A.G v.s. SFT?
This question will become less relevant as agent application started booming in 2025, the short answer is both, think about how humans solve a problem:
- We search for reference when we couldn’t recall from our memory (and being aware of this not recalling)
- After we obtain new references, we learn and update our memory with new facts/data.
Soon LLM is going to progress to a very, very strong state on 1. On 2 it will be behind humans for a while, meaning it cannot absorb, and internalize data in real time, hence, external memories and agentic orchestrators will be built to mimic human’s cognitive architecture on “memory”. R.A.G will become an integral part of this process; whereas SFT is always task-specific, what particular objective do you want the agent to do better than “context-free” models?
Q4 – how to know if my SFT has introduced regression on base model?
In other words:
How to maintain strong alignment during SFT so that the model stays consistent, faithful, and strong reasoning as the base model?
There is really no way to probe its internal “alignment state” besides running tons of evals, ideally, imagine we have a comprehensive golden eval dataset to benchmark the “alignment” state after fine-tuning, ideally we want:

Here since LLM outputs are text “tokens”, we should not expect identical output tokens. For example in math problems twenty-six are equivalent to 26 (this can be mitigated by using more instructions on output format)
In real world applications, especially agentic scenarios, there is very little tolerance for variance of this benchmark — for trustworthy “agent”, people expect it to robustly respond and execute, so imagine not only you need a good benchmark but also have to suppress variance to <0.01% — to put it perspective, many handcrafted benchmarks are seen as high as 5% AA variance across runs.
To tackle variance, public benchmarks can be used as proxy for the golden set, a few notable ones include:
- Humaneval
- MMLU
- SWE-bench-verified
There are huge issues with using these benchmarks, first of all these are pretty saturated on nowadays SOTA LLMs, especially when you train on post-trained checkpoints, you’d rarely observe “real regression” on these benchmarks; second you cannot prove “safety” with no-regression and disprove when seeing regression. The base checkpoint is well picked to reflect the best state on these scores.
As a result, in recent years the evaluation of “alignment” is relying on “crowdsourcing”, each each area of experts doing their own “judgment”, e.g. the most crown jewel is chatbot arena where the capability test is mostly on chat helpfulness, and other eval grounds are twitter and reddit forums where people throw anecdotes until a few months out where folks sort of agree on an “undisputed” champion.
Recently some private eval set has gained ground. The leaderboard of these benchmarks are roughly aligned with crowdsourcing opinions, which increases the credibility of these private dataset.
