What is Self-Reflection?
Self-reflection is one of the key primitives to unlock AI Agent. It’s already heavily studied in AI Alignment research. The definition is super simple, in agentic workflows, agent’s execution is defined as a sequence of state-action pairs:

Here the transition from t to t-1 is governed by the environment (external feedbacks), self-reflection is agent’s intrinsic policy that determine the next-step actions:

This is internal to the AI agent, basically it governs the next step to do after observing the current state. In AGI scenario, the action space can be unlimited, while in our interest we normally refer to the typical actions in software engineering like writing code, querying/updating database, controlling browsers etc, for example, imagine the following “what to do next” scenarios:
- Self Critique: after emitting some thoughts, doing some self check and correct its own mistakes if found
- Propose alternative thoughts in parallel to current thoughts
- Hypothesis test: make an assumption, collect data, calculate stats and verify the assumption
- Counterfactual evaluation: “what-if” scenarios, imagine what would happen in the proposed alternative scenarios in 2, evaluate the impact, and decide what next.
1-4 really makes an Agent “human-like”. An interesting question is, how is self reflection defined as a “capability” and how is it differentiated from other capabilities? I’m going to throw some subjective points here: I do believe self-reflection is a particular “capability” that is orthogonal to others, for instance, these capabilities are not considered as “self-reflection”:
- Understanding a particular domain of knowledge: being a deep domain expert will definitely help you make decisions quicker to jump to the “short-cuts”, however it does little to reflect the agent’s actual reasoning skills. This is like memorizing a large amount of key-value pairs of “state–action” decisions, such memorization will definitely help, but it couldn’t generalize cross domain.
- Common-senses: human society accrues a large amount of “tribal knowledges”, when encountering a scenario, such common-sense governs what to do v.s. what not to do. A fun observation is that in agent applications users usually have to careful enforce rate limit otherwise the agent will run tokens crazy since it has no sense of “frugality” by itself. There are tons of similar common-sense, such as understanding time, date, time ranges, concepts like early/late, last/recent, before/after. Long term v.s. short term, seasonality. These common-senses are orthogonal to “reasoning skills” as what’s demonstrated with self-reflection, the decision P(a|s) is not achieved through intelligence but rather memorizing scenario-to-action pairs.
I intentionally draw a line between ‘memorization’ and ‘self-reflection.’ While memorization involves recalling specific information at a given state (St), self-reflection emphasizes the development of general problem-solving skills. People have good faith that LLMs already acquired such skills by learning from massive problems and solutions corpus.
In the following sections, I’ll give some capability axes I have categorized when developing agentic workflows. These axes I believe are necessary conditions to achieve “self-reflection” capability. In 2025-2026, I’m mostly interested in the research and evaluation on these data/problems as it marked the advancement of foundational models towards this direction.
Strong LLMs are Intrinsically Calibrated
Let’s ask a simple question to begin with:
what is the LLM’s “confidence” when answering a question?
There are numerous studies about this, forgive me of not quoting any of them, here I throw the conclusion from my own experiences:
Strong LLMs are well “calibrated”, depending on the task, good calibrated cases can give 99% “high” confidence responses (in which case they know they are high confidence).
Higher confidence response is crucial for agents to behave “consistently”: a fun quirk is ChatGPT users keep grilling the model “are you sure?” until it (mentally) break-down. When solving complex problems, we need to ensure agent gives assertive response at every single step in long execution steps, in order to produce consistent end conclusion. There are 2 implications of being consistent:
- The agent’s execution is reproducible
- When it makes mistakes, the agent can be fixed consistently.
Interestingly, very few serious research has put into this axis, while agent practitioners struggling with inconsistent behaviors in real world executions.
One thing to disambiguate is “confidence” v.s. “hallucination”, during our practice, the likelihood to hallucinate is almost identical between high and low confidence responses. In other words, there is no reason to believe an agent will “confidently” make less mistakes or more. “Hallucination” is historically considered a “pre-training” issue and has been largely resolved with strong post-training/alignment methods in the recent 2 years, hence we should rarely see SoTA LLMs hallucinating, except for very difficult cases where humans are also prone to mistakes.
Code Execution Feedbacks
LLM Agents have been particularly seen working well when seeing code execution feedback. For instance, when it sees the execution results of a snippet, it’s immediately aware of doing:
- Attempt to debugging if it failed
- Reflect on the execution results and proactively decide what should do next
This is quite surprising given the typical “reactive” picture of LLM. So why does it work so well? Here I provide a few of my own hypothesis:
Hypothesize 1: SoTA LLMs are trained on code execution feedbacks
It’s unclear if GPT4 or Claude is trained on them. Here we briefly summarize the OSS pre-training/post-training recipes as of 2024 year-end, imagine the code execution feedback were to be trained in SoTA LLMs, it would have to go thru:
- Pre-training on a document that contains instructions → code → exec results → next step → code
- We do have a considerable amount of “trajectories” like this in pre-training corpus, i.e. StackOverflow question-answers, etc.
- SFT with multi-turn conversation style: instructions(user) → code (assistant) → exec results (user) → code (assistant) → …
- In LLAMA 3 technical report (similarly QWEN, DeepSeek etc) I’m not able to see such trajectories explicitly mentioned in SFT sections.
- RL with execution feedback (RLEF): directly use execution feedback as reward. This is still a new research directions:
- This is likely what OpenAI’s O1-O3 line of methods are doing
- DeepseekV2 mentioned fitting a reward model using compiler feedback, but it’s not likely the key technique that produces the maximum benefit.
- [Update on 12/26/24] The latest DeepSeek V3 is a BANG!
- LLAMA 3 does not employ such a method, but still demonstrated good AI coding agent performance (there are LLAMA 3.1 based agents that scored top 5 on SWE-bench in mid-2024).
Hypothesize 2: it’s only pre-trained on code corpus, but somehow obtained the self reflection capability even w/o execution feedback.
This becomes very interesting, if actually proved to work, it points out a feasible path to boost self-reflection capabilities.
One possible proof of this is that, when testing LLAMA2 and G3.5 I do see some successful examples of models reflecting on code execution feedback and deciding the next step to do (beyond 5 steps), while GPT4 has much higher success rate due to better instruction following and lower hallucination.
But how? The pretrained code corpus is just concatenated code snippets. One explanation is that the pre-trained corpus already contains “execution feedback → next step” decision trajectories like the StackOverflow dataset, but there lacks a quantitative study of how this scales. I would particularly be interested to look out for 2 types of quantitative studies:
- How directly learning these code execution feedback trajectories improves agentic workflow success rate, how does it scale with the amount of trajectories.
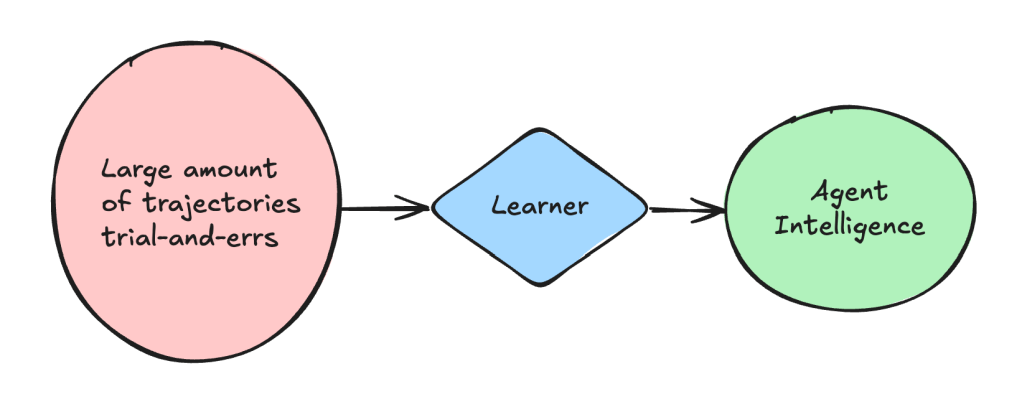
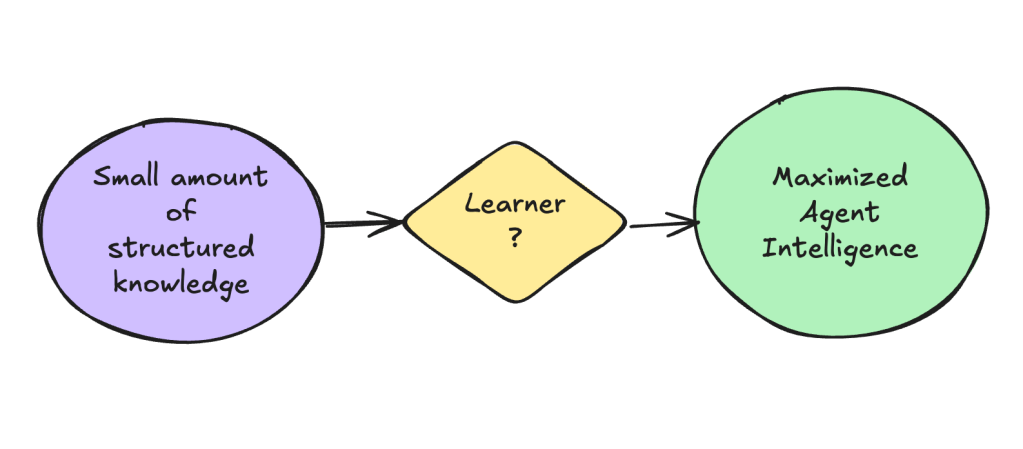
- Cross domains transfer: for example, if an agent learn from some structured knowledge, or rather, just directly reading the code, can it still improve agent’s performance?
2 is quite relevant in real agent applications, it’s not feasible to collect a large amount of “trajectories”, however structured knowledges like code, documentations are prevailing, and often times are the ONLY learning material for the agent. I particularly like the concept of directly learning from code — it’s the most compact, logical information of an organization, and it’s the perfect representation of “business-logics” or whatever that is. The current research direction like OpenAI’s o1-o3 (survey) is deviating from this track (though they already achieved large scale RL training), it’s heavily relying on search and outcome based verifier to improve the model, the training cost is going up instead of going down.
Long Context Degradation
There have been numerous studies on this, for various tasks, even SoTA LLMs like Claude 3.5 Sonnet, GPT-4o, Gemini 2.5 have experienced performance hit when context is above the original pretrained length (starting from 8-32k). In the context of self-reflection, the question is, how does the model “stay focused” as context accumulates?
Existing benchmarks are retrieval and summarization based, these are more or less inherited from traditional NLP studies, but they are not identifying the “focal point” of the model.
As an example of typical agentic applications, the model shall be equipped with a high level goal, i.e. “refactoring this repository of code from JAVA 18 to 21”; while during execution, the agent is bothered by a huge log of previous events, hence risking “losing focus” of what to do next even though it can make good local decisions. In our experience working on such applications, the degradation may not matter as much as absolute token length, but rather the amount of information the model needs to process at once — the more “distraction” of previous events, the worse the performance of the agent (measured by per-step decision making, aka, process based supervision). The real lessons learned are:
- SoTA models like GPT4/claude 3.5 Sonnet still are behind human, it tends to:
- Early stop
- Arrive at drastic different conclusions even tho the instructions are pretty clear
A few notable methods have been proposed to improve on this axis:
- Better tuned prompts:
- More clear step-by-step instructions, no ambiguous terms
- Better CoT style reasoning template (will expand this later)
- Resampling: run the agent multiple times and apply self-consistency based verifier
One promising research direction to really tackle the challenge is “process-supervision” for agents, aka process-reward-models (PRM) (see OpenAI blogs). In addition to outcome based supervision (end reward model), PRM nudges the agent to mimic more human problem solving: evaluating each step and basically know what it’s up to:
Step → Evaluate → Identify Task → Action → Step → Evaluate → Identify Task → Action …Note this is different from “planning”, planning is more like math, deriving a chain or graph of tasks given a high level goal. Here we are talking about “focusing”, which is a LLM idiosyncrasy to de-noise from a large amount of context. For example:
The agent may be doing a simple local task out of a master plan, e.g. querying an API, however the API returns a giant blob of logs that quickly filled up agent’s context, will the model still be able to pay attention to original the querying parameters at the beginning from the giant pile of logs? Will the agent proactively “drop” such useless logs (assuming it has tools to prune itself)? These are the capabilities we are primarily interested in.
To be playful, consider how humans greet each other—a practice found in nearly all languages:
Hey, what’s up?
Notice how humans constantly assess the current situation and figure out the task at hand. In contrast, existing agentic workflows typically require detailed, step-by-step user instructions to inform the agent of what it should be doing.
Up until 2024, PRM has mainly been used to guide models to follow correct reasoning trajectories when solving math problems. What I’d be interested to see is how LLM can actually learn from PRM’s step-wise feedback to know how to focus. It’s hard to believe such skill can be generalized from MATH problems, since humans really can do this for a broad range of tasks. For example in software debugging, the context can be huge amount of code/logs, yet human knows what to focus on after each step of investigation.

LLM-as-Judge
LLM-as-judge CAN work, it’s already widely used in almost every public LLM evaluation benches (there are still exceptions like Chatbot Arena which I believe is still human based). A few observations:
- The judge’s “accuracy” varies across tasks.
- It’s also the basis why search based optimizations can work in agentic explorations (ToT, Reflexion, MCTS).
I have found a very nice theoretical paper for LLM-as-Judge by OpenAI in the 2022s: self-critique. Let’s first throw some important definitions:
- Critiqueability: Given a question, and an answer to it, output whether the answer contains flaws
- Critique: Given a question, and an answer to it, output a natural language critique of the answer
It’s noteworthy that LLM-as-Judge works b/c of 1, not 2, this leads to the important measures of generator – discriminator gaps for self critiques. Consider the following 2 gaps:
- Answer generation v.s. critiquability: model’s ability to know when answers it produces are poor. A positive gap corresponds to ability to improve outputs using a discriminator
- Critquability v.s. Critiques: model’s ability to give human-understandable critiques on answers it “knows” are flawed (and inability to give convincing critiques on sound answers).
Similar to most LLM-as-judge observations, the gap is task-specific. For example, the author measures a few synthetic tasks:

a) 3-SAT: a boolean equation solver task, the gap between generation and critiques are clear – obviously it’s much easier to evaluate a formula than solving equations
b) RACE: reading comprehension, which is a more interesting task – the gap is much smaller, however there is a clear gap between critique and critiquability (also is closing at larger model scale as indicated by SFT loss – the author only does fine-tuning)
Regarding scaling law of critiques, this paper was released during 2022, in which time OpenAI is still actively studying scaling law and there exists heated debates around “emergent capabilities”. Nowadays, debating “emergent capability” has less value, while some charts showing the closing gap between generator discriminator at scale, it’s not convincing enough (author also admits it) – hence, LLM-as-Judge will work for a while, meaning we can always design critique – self-refine agentic flows to improve performance and use eval-driven approach to assess task performance.
Agentic Long Term Memory
This is a related topic to long context. A naive question to ask first, why something like ChatGPT memory can work? (Anthropics had something similar) In academia, MemGPT is a really nice agentic architecture that depicts (not to say it realized) such a system, where the agent can:
- Aware of when to store/retrieve
- Aware of its own context limit?
Another in-depth discussion of this topic in the CoALA paper (alpha paper on agentic architecture), which tries to categorize design patterns for short-long term memories. The question is how, and to what extent will agent operate its own memory?
Let’s first look at system design of agentic memory, with good hope that memory system design shall have some impact on this capability, considering the following designs:
- Rolling buffer
Agent refreshes its context with a FIFO style queue manager, so the earlier context/messages will be discarded. In this case the agent has no long term memory. Hence it won’t be able to process long running tasks (each task is processed one-off), not able to correlate in between tasks, e.g. aggregating conclusions from a large amount of task executions.
- Knowledge Graph
This is useful to store/retrieve factual knowledge. In Anthropic’s example, it’s essentially nudging model to recognize entities and relations (a typical NLP task that LLM is already proficient at). This shouldn’t require strong self-reflection skills, as the only thing the LLM needs to do is recognize “facts” and store them, and retrieval is done by sophisticated KG systems.
- Memory Hierarchy
With a memory hierarchy, Agent now becomes an Operating System (OS) that manages memory operations that were traditionally done by heuristics algorithms. This also resembles how human memory works (not to say humans memory is efficient and accurate, in fact it’s neither). Imagine the agent needs to operate the following:
- List: a list of recent events stored in an array that can be traversed in order for revisit.
- Key-value pairs: just like typical databases
- File-tree: agent will use the file name index to store/fetch information blocks, it’ll also update the tree structure on its own.
- Text DB: support keyword search
- Vector DB: support similarity search
As you can see, an agent needs to be quite familiar with the pros/cons of these databases to operate on its own. Unfortunately there is not enough research into how agent can learn & improve operating these databases. I do think the future is bright, with a plethora of database types agent can have memory that’s much more efficient than human.
Self-Reflection is not Self-Awareness
In Ilia’s talk in 2024 NeuralIPS, there’s mention of “super intelligent” AI with self-awareness. But we are not interested in super intelligence AGI, my own conviction is that: agent CAN work, achieving agent does not require AGI or super intelligence. We just need to have LLMs learn general and specific problem solving skills to handle complex automations. The innovation is more on dev efficiency (reflecting on the “software complexity” curse in chapter 1), that agent can achieve automations that are normally exponentially harder to build by traditional softwares. In return, we get great productivity wins, not just reducing software engineer years, but enabled some completely unknown scenarios, such as:
- No more oncalls, infra system can self-heal, self remediate, and self-recover
- Building and maintaining websites with AI Engineers
- Building robots with AI Engineers
- Completely automate medical diagnosis and operations
These, to me, are the true future of agents, and will already bring so much value to the society even before AGI arrives.
