Agent is such a fascinating topic in 2024, it’ll take a long series of effort to talk about Agent. In Chapter 1, I’ll put out a conceptual view of Agent, in later chapters will dive into detailed design and ML topics.
Before we talk about Agent, lemme ask a question first:
Why Is Modern Software Designed This Way?
The Unpleasant Truth About Software Engineers
Let’s start with a few basic observations, imagine you’re an alien who possess much higher intelligence than human, you just arrived on earth, and you become curious on software engineering. After you check it out, you immediately start to ask the following questions:
- Why your homo-sapiens created so many programming languages?
- Why can’t your homo-sapiens directly program the hardware? What’s the difference between “software” and “hardware”?
This might sound absurd, so let me put out my arguments in an different angle. Imagine you’re an average software engineer with 5 years experience, pretty senior right? At one day you are assigned a side project, you need to finish up today and launch tmrw with a fair quality, here are the options for you:
- A simple game, almost identical to the Snake game, except now there are multiple snakes – you control one, and if you collide into one of others you lose; you will implement it in Android, and another day to convert it to IOS.
- You’re given a robotic arm and Arduino board, program the robotic arm to fold your shirt.
1 may make you frown a bit, and 2 will surely make you flinch – it took robotics researchers/specialists, surely more than a day, and surely working at bare minimum that can break easily, works 1 out of 10 when folding your shirt, depends on what your shirt looks like.
As simple and intuitive as these cases sound, as developed as modern technology, and as much as we’re trained “engineers”, sadly, we cannot finish these tasks easily. Don’t get me wrong, the software industry has advanced so much in the last few decades, there are high level “frameworks” for you nowadays that makes you 10x faster than 10 years ago, or 100x than 30 years ago, but still, these don’t feel like an easy task that can finish off in a day.
It all comes down to “complexity”. Human has inherit limited ability to handle complexity, whereas building software comes with immense complexity, here’s how to complexity grow in my mind:
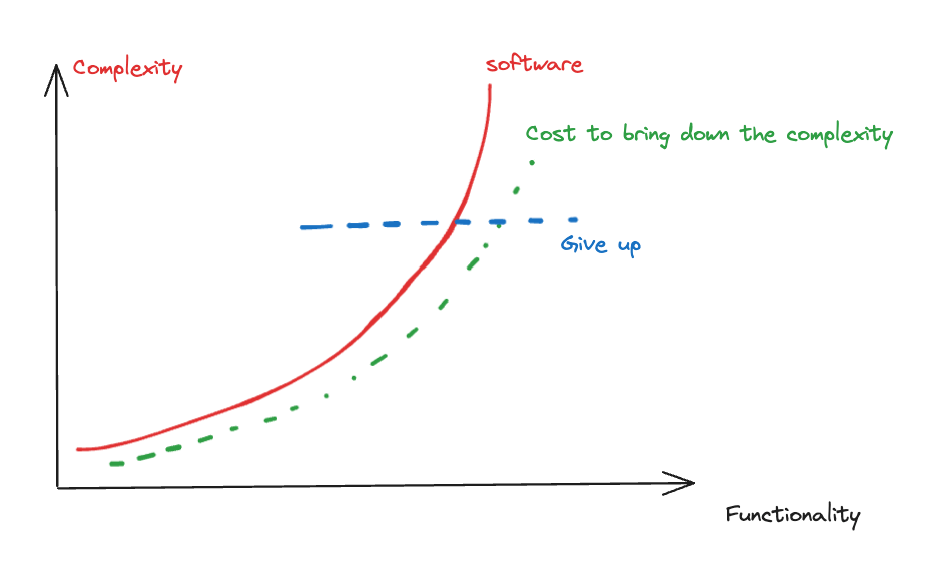
As functionality grows, it cost exponential amount of effort ($ and people costs) to bend down the complexity under human-level control. In the above android example, you don’t directly build on top of linux, Android as a middleware handles most of OS level complexity for you; in the robotics arm example, there are high level APIs nowadays that wraps complex motor controls for you; a more prominent example is in game development, game engine helps you handle complex physics simulation & rendering. Essentially today’s software development looks like Jenga building

I have mixed feelings on this jenga building pattern. First, it does reduce human communication cost during software development, but it does not help to reduce the complexity of the software itself, in fact, it makes it much worse – going back to the Android development example, your snake app is prolly using 0.1% of all functionalities provided by android, so your tiny little snake game is carrying mountains that you wouldn’t even need 99.9% of it! That 99.9% means wasted memory, wasted compute. As a seasoned software engineer myself, whenever someone sells a “framework”, or “service” that claims to “drastically” reduce complexity, I don’t take it with a grain of salt — I take the whole bottle. What we do see is, very often, people just give up: engineers give up, so do managers, investors, and customers.
Such cost cut-off threshold has profound implications, for example, the electric control box in my garage door – how it works is that I press a remote, it open and close the door for you, I was often annoyed at myself forgetting to close the garage door, why can’t the software in the control box just monitor my status and close it for me? The answer is the cost is too high for building such functionality, so the vendor just gave up.
Now comes the era of LLM. So what does it give us? The answer is simple: it can handle complexity way beyond humans — if LLM can read an entire book of “The great Gatsby” and recall perfectly paragraphs, would it be able to build softwares 100x complex than humans?
The Dumb Imperative Programming
Existing world’s softwares are built with “Imperative Programming”, pretty much any programming language you encounter is imperative programming: C/C++/JAVA/Python, you name it. These programming languages satisfy “Turing Completeness”: meaning the ability to represent any algorithm.
To a non-techie, “algorithms” might seem like divine magic. But truth be told, while 0.01% might dazzle like God’s handiwork, 99.99% are just plain old dumb control flows — so dumb that they typically look like this:
result = call_func_1()
# control flow
if result == 1:
call_func_2()
else:
call_func_3()A “control flow” does not mimic human problem solving at all. Humans have much more holistic decision making skills – I hate to use a weasel word “holistic”, but this one is relevant, it means handling a large amount of observations (input) and actions (output). While in control flow if you try to author a large amount of input/output programs, you’ll be killed by complexity as I mentioned above.
Humans also have strong common-sense, and are able to handle fuzziness, such ability is far from what nowadays imperative programming can do.
Think about hiring a robot house cleaner, you tell her to vacuum the carpet, and she sees a rug on a wooden floor, and she’s stuck cuz she wouldn’t know if that counts as “carpet”? So you go and reprogram her to include “rug on a wooden floor should be vacuumed as well”, and it keeps going, and finally you realize it’d take her 10x of time to clean your house than doing yourself, so you stop hiring her – your give-up threshold.
To spice up the criticism, I’d also like to quote my favorite argument which is Searle’s Chinese Room:
Imagine a man who only speaks english sitting in a room, he was given an instruction book, which tells him how to remove/add/modify characters, the instruction book is so perfect, that given a question written in Chinese, he can “write” an answer that astonishes a native Chinese speaker as masterpiece, but the man has no idea what he’s doing instead of stitching up characters!

The criticism comes down to the core question:
How can we write programs that can actually exhibit some level of human intelligence?
Agent is Cognitive Software
I have so far written a great deal about complexity and control flows, and now I finally lay out my interpretation of what is a LLM Agent: it’s a cognitive software that has potential to break the barrier of complexity and control flows. In fact, cognitive architectures is not a new concept, this has already brought up in day 1 of computer science, see Cognitive Architectures for Language Agents has shown a history of studies on this topic.
Here I drop my own definition of cognitive architecture, it’s built upon the following fundamental capabilities
- Memory
- Decision Making
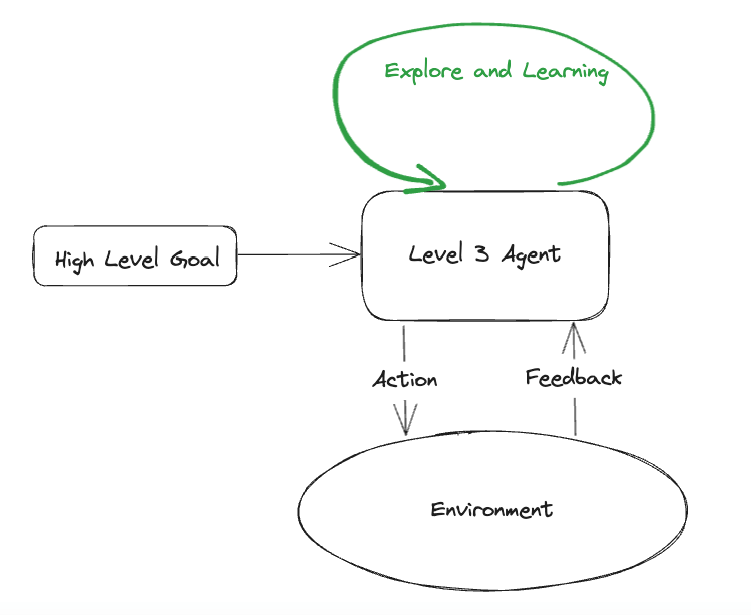
- Exploration and Learning
I will use the later chapters to put into details on each capability, before we do that, I want to point out that the term “agent” has really been abused nowadays and causing major confusions often. To differentiate our conceptual framework of agents v.s. others, I take a similar approach to self-driving cars industry, provide a “classification view” based on agent’s capabilities, I call it the “agent diagonal matrix”:
| Agent Classification | Memory | Decision Making | Exploration and Learning |
| Lvl 1 | Y | N | N |
| Lvl 2 | Y | Y | N |
| Lvl 3 | Y | Y | Y |
Lvl 1 is a simple R.A.G based Q&A system, it’s a one-step process w/ no decision making involved, the retrieval system (memory) is an important building block where most of the optimizations happen, and LLMs are more like the storytellers, summarizing and making sense of the data.
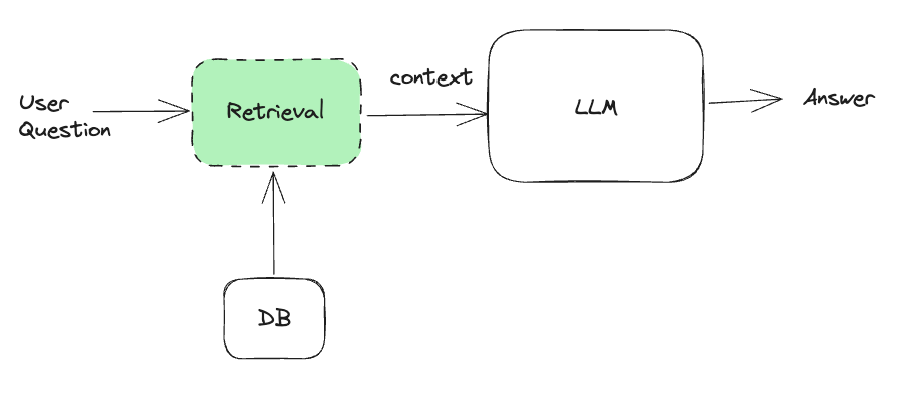
Starting late 2023-2024, Lvl2 Applications start to emerge, to name a few pioneer projects:
Provide boilerplate code for creating more complex GPT agents (see tutorial, and one agent example), as well as benchmark + leaderboards, the benchmark supports simple code generation, code modification and memory tasks (which seems GPT4 can reach 100% acc)
Provided multiple agent implementations and designed multi-agent interactions.
A chatbot framework that uses ChatGPT to intelligently store & manage short term & long term memory.
Assign different roles to GPTs to form a collaborative software entity for complex tasks.
Interpreter supports Python/Jupyter/CLI/Javascript, moving to more IDE level support.
Lvl2 is indeed making multi-step actions and aware of the consequences. What Lvl2 lacks of is learning and adapting to new knowledge. For example, explore and learn new tools & environment, breaking down big tasks into smaller tasks (planning). Put it simply, in Lvl2 you need to teach the agent to make decisions (few shot prompt), Lvl 3 is it’ll make its own decision, human just providing high level guidance.
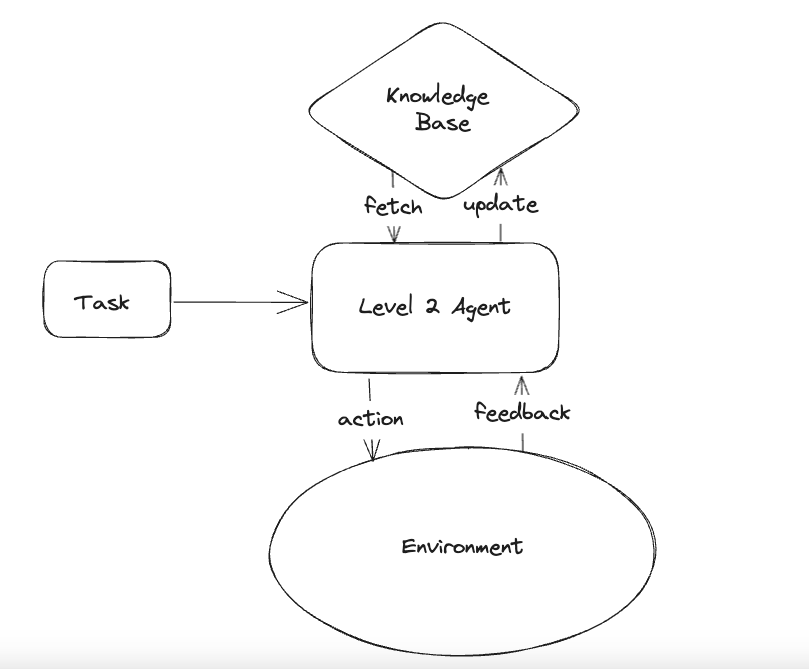
Lvl2 has been happening in recent 2 years. A standout example is Devin from Cognition Lab, which has certainly caught some attention.
It’ll be foolish to deny the possibility of Lvl 3, my own prediction is that it WILL HAPPEN in 5 years, I’ll explain in later sections where my prediction is based.
In the next few sections, we’ll have a preview of how these capabilities are built, we’ll further expand on ML & system design in the upcoming chapters.
The Role of Foundation Model
The underlying foundation model determines agent classification.
For example you cannot expect to build a Lvl 3 Agent with Lvl 1 model. When developing Agents, the foundation models are measured in the following dimensions:
- Reasoning
- Planning
- Self-reflection
The 3 dimensions are not orthogonal, we provide this breakdown b/c often times we can benchmark each of them separately, however the actual state of them are intertwined. For example planning is correlated to reasoning, self-reflection is correlated to both reasoning and planning.
1,2,3 are also directly correlated to hallucination. Hallucination are broadly categorized into the following
- Factuality: are the facts stated in the response consistent/supported by the context in the question? Did the response fabricate facts or data that are non existent in the question’s context?
- Faithfulness: did the response align with the question’s intention? Did the response follow the instructions and guidelines mentioned in the question’s context?
- Logical: is the final answer logically coherent with its reasoning? Are these any logical contradictions in its reasoning, calculation and estimations?
See A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions as a good survey paper on this topic. From my experience, The 3 dimensions form the “trident” to ensure model output faithful, logical and factual responses. “Self-reflection” is a overlooked dimension, to me this is the most critical skill dimension, self reflection is the sufficient condition for alignment, which includes model’s ability to follow instructions and robust to prompt perturbations. A next level achievement of self reflection is awareness and proactive, think about the following:
- How good can LLM fix its mistakes given external feedback thru multiple rounds w/o getting lost?
- Can LLM ask you for confirmation, or proactively establish a checklist to clarify your intention before responding?
- Can LLM provide “critique” to your question, or even self-critique its own answers?
Self-reflection is still at early research stage, to quote a few relevant papers:
- Self-critiquing models for assisting human evaluators
- Language Models (Mostly) Know What They Know
- Large Language Models Cannot Self-Correct Reasoning Yet
- Reflexion: Language Agents with Verbal Reinforcement Learning
When self-reflection reaches a very strong stage, it means it can efficiently explore the environment w/o losing its goal, it knows what it needs to learn, and proactively seeking information to learn it.
How will the 3 dimensions affect Agent classifications? For Lvl1, none of the above is relevant, since Agent is not making decisions and perform actions. For Lvl2 agent, it may not need strong planning skills, b/c the plans are already given to it (knowledge base + instructions), but it needs to have decent reasoning and self reflection to perform multi-step actions. For lvl3 agent, you expect it to be strong at all 3 to explore environment in the wild, just like humans.
| Agent Classification | Reasoning | Planning | Self-Reflection |
| Lvl 1 | Weak | Weak | None |
| Lvl 2 | Medium | Weak | Medium |
| Lvl 3 | Strong | Strong | Strong |
So how good is today’s LLM (Mar 2024) at these 3 dimensions? Here I drop some unfavorable opinions of today’s SOTA LLMs, purely from my own experience in this space (which I consider above average):
- Lvl 1 models: LLAMA2, GPT3.5, Mistral
- Lvl 2 models: GPT4-5, Claude3 Opus, Gemini Ultra
- Lvl 3 models: GPT6, Coming in 3-5 years
If it’s all about the foundation model, what do agent developers do then?
In fact, there are a lot of works to do, more than writing traditional softwares.
The very first job is DATA, there’re 2 themes coming out of the data effort:
- Data Pipeline
You may think of data pipeline in the “Big Data” era, but it’s not. The LLM data pipeline is completely different, it doesn’t need to process billions of records, or perform complex ETL operations. The data size is prolly 3 magnitude smaller, but it needs to be precise: every single document matters, it needs to be vetted, cleaned, plus some human-in-the-loop as supervisor. So far I have seen none of such successful enterprise applications, LLaMAIndex is a very good start, taking a community effort to tackle this challenge. Think about this, today’s data in the wild are super LLM unfriendly, too many implicit knowledges hidden in the doc like:
- Links: LLMs just can’t understand/denoise links very well (yet).
- Charts: today’s multi-modal LLM cannot precisely read charts and capture details
All of these make data pipeline effort a hero-effort.
2. Evaluation/Benchmarking
Unlike writing unittests, today’s agent application is verified by benchmarks. For each use case, collect in a set of high quality evaluation set is essential to verify/tune agent implementations. This is an extremely time-consuming, and often times confounding work, as confusing as the data collection work.
The data effort is likely to be different for each classification level. Ideally, Lvl3 agent has very strong de-noising, navigation (exploration), coding abilities to automatically compile a list of documents from the wild.
3. Feedbacks, Feedbacks, Feedbacks!
The third important thing is designing external feedback + sampling mechanisms
Why are these important? I’ll expand on this part in the upcoming chapters. To provide high level understanding, I’d like to quote an interesting diagram from AlphaCodium:

In the above diagram, blue is seen as the correct solution space, red is the LLM’s initial “guess”. External feedbacks + sampling iteratively guide the LLM to correct sample points. We’ll further explain details on how to design this feedback process, it’s a fascinating journey of realizing how reasoning + self reflection empowers the agent to explore the right path.
Besides the most important 2 things, there are indeed useful tricks during agent design & implementation, we’ll expand on this in later chapters, to name a few brilliant ideas that are proved to be useful:
- self-consistency
- Reducing context length: this argument is somewhat controversial, I will expand in future chapters
[Personal opinion only] some of the ideas, however, are not yet proved useful and do need extra scrutiny:
- Chain-of-Thought: it just won’t work on some models. Is today’s LLM actually able to propose “thoughts”? To me the conviction of “thought” is very flawed: to me “thought” is tied to the domain knowledge of the given topic, it does not relate to planning, reasoning and self reflection skills.
- Multi-Agent, i.e. Autogen, how is this different from a single agent implementation? what benefit does it actually bring?
In the next section, we look at the actual implementation of agents.
LLM-Program – Old Dog New Trick
We put a soft definition on Agent and provide some soft justifications on why it would work, and now let’s take a look at how Agent is actually implemented.
Here’s what an AutoGPT-like program looks like:
while True:
input = observe() # text representation only
output = agent(input) # text representation only
# now finally comes the normal part of programming
action = parse(output)
perform_action(action)
This looks so sketchy! Will it work?
In “traditional” software programs, probabilistic output only appears in large scale distributed systems, in this regard, fault-tolerant and recovery are advanced topics, mundane programmers don’t care, not every coder is Jeff Dean
With LLM program, fault tolerance and recovery suddenly becomes the most essential topic, redundancy, retry, and consensus algorithms will be ubiquitous in Agent implementations.
Let’s look at some real-world challenges of such type of implementations:
- Exponential Error Growth During Multi-step Execution
Let’s say your program involves N steps of calling LLM, each step has 0.8 probability to fail, during execution, the likelihood of failing is 0.8^n.
- Lack of External Verifier
Human is usually the best “babysitter” of LLM response, in Agent implementations, you just let go, the program has no idea of the “state” of your LLM, how do you “verify” the output of LLM and help determine next steps?
- Lack of Planning Capability
In essence, we hope the agent can do the following, here I use example proposal of ADaPT:
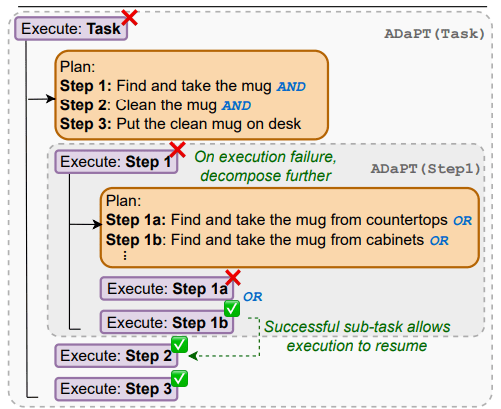
The fact is, such planning is still very hard for today’s LLM. Mitigation methods of lack of planning will be discussed in upcoming chapters.
Different levels of agent may see the challenges differently, for instance, here’s a view of whether the challenge exists for each level (Y/N)
| Lvl/Challenges | Planning | External Verifier | Multi-step Execution |
| Lvl 1 | – | – | – |
| Lvl 2 | Y | Y | Y |
| Lvl 3 | Y | N | N |
If you see these as college basketball programs, Lvl2 above are serious Division 1 schools, Lvl1 is out of the league, it wouldn’t even face these design challenges. Lvl2 did hit EVERY challenging point! It basically needs to find mitigations to all the 3 challenges. As a result, people:
- Wait for Lvl 3 to come – this is the attitude of most of the ppl
- For planning, maybe we can alternatively design a “planner” as an auxiliary model of LLM?
- Fine-tuning on domain data to make the LLM become domain expert?
In the next few chapters, I’ll try to answer these questions from my own practice in this field.
I expect Lvl 3 agent to be so good at self reflection that it’ll never get lost and can execute unlimited steps; it can also actively explore the external environment, and beware of whether the feedback is a valid “verification” of its execution, hence no need to carefully design feedback mechanisms for the agent.
Planning is a huge question mark, just like humans, if you’re not an expert at something, you have a high chance to fail: you might be good at the Sokoban puzzle, or you might suck at it, but it doesn’t deny you an intelligent human being. We’ll expand on domain knowledge learning/ingestion in future chapters.
The future is bright, But
Our world is still 99.9999% written by “traditional softwares”…which makes no sense.
Our tools, document format (PDFs, yes, I’m naming names), UIs are built for human perception, which are super anti-LLM, which favors clean formatted text input.
Think about almost EVERY tool in this era is unfriendly to LLM:
- The webpage source is huge blob of html + Javascript, not friendly at all.
- The UIs, optimized for human “actions”, its control and navigation is extremely inefficient for LLM and requires multi-modal – but does LLM really need to read images? Your visual energy will be depleted by browsing all the websites of the restaurants in your city, but you can shove all of their menus into LLM context window, no problem!
- APIs and code are better, but requires understanding a huge amount of context (a single 1000 line python code file takes 10k tokens!)
There’re also Bot protection, anti-scraping mechanisms. To me, these are not necessary in LLM world, a LLM act just like human, and it won’t DDoS a website cuz that’s just too expensive: would you DDOS a website with 1000 GPT4 calls, each processing millions of JS+CSS tokens for a single page? You’ll surely be broke.
There’s going to be a long way for the software community to finally acknowledge the power of LLM and adapt an AI-first programming model in mind. I don’t know how long this will take. Apparently, when Lvl3 agent actually comes, it’ll be a huge blow to the industry to move towards AI-first softwares. I’m just too excited to witness this in my career, let’s build the future together!

One thought on “LLM Agent Studies Chapter 1 – Cognitive Architectures”