In this post we talk about an interesting direction regarding parameter efficient tuning for LLMs — prompt-tuning: meaning using gradient information from LLM to construct soft-prompts; prompt-tuning, compared with finetuning, is much cheaper for LLM users to adapt to their downstream tasks:
- Freeze the LLM weight completely, potentially can work with any LLM interface.
- Zero-shot only, no need to manually craft prompts for the given task.
- Sometimes CAN work on extra small, low diversity/quality dataset, which is often the case in wide range of downstream LLM applications, will prove in later exp.
Here we experimented prompt-tuning with initialization from human engineered prompts, the inspiration comes from the 2 papers: https://arxiv.org/abs/2101.00190 https://arxiv.org/pdf/2302.11521.pdf
We focus on a few tasks that LLM is believed to suffer from:
- Simple arithmetics, add 2 large numbers, multiply etc.
- Symbolic manipulation: like “x1=1, x2=2, … xn=10 sum(x1+..xn)=?” being able to substitute for symbols, and recursively/literately apply arithmetics. Classic example would be sum of arithmetic sequence.
- Word manipulation: reverse the letter of a long word
- Last letter concatenation: given a list of words, concatenate the last letter of them togehter.
We use NanoGPT, the weakest LLM released so far ever, will later add on support for LLAMA 7B etc. much stronger foundational models. For the above 3 tasks, it is super easy to curate our own dataset, for example, here’s a random generator function that can produce digit-by-digit steps to add 2 large positive numbers.
import random
import numpy as np
def generate_addition(a, b):
# text = "%d+%d;" % (a, b) # symbolic form
text = "%d+%d=" % (a,b) # non symbolic form
carry = 0
s = a + b
while True:
# text += "%d%d%d" % (a % 10, b % 10, carry)
text += "%d%d%d" % (a % 10, b % 10, carry) # alignment mode only
# if a == 0 and b == 0 and carry == 0:
# break
# aignment mode only
if a == 0 and b == 0:
break
text += "%d;" % ((a + b + carry) % 10)
carry = (a % 10 + b % 10 + carry) // 10
a = a // 10
b = b // 10
text += "=%d$" % s
return text
generate_addition(321, 654)
---
'321+654=1405;2507;3609;000=975$'
We do not use GMS8K etc. public dataset since we’re not here to achieve SOTA fine-tuning results but merely to demonstrate the ease of use of Prompt-Tuning, prompt-tuning can certainly not beat Finetuning on these public datasets, but it’s the fastest way for LLM applications to use.
If we straight train a transformer using the curated dataset, we’ll have super performance, of course the model is ONLY trained to do this task, nothing else!

Basically I tried a few tricks, and turns out simple is best, 10 epochs with roughly 20000 random examples can reach 100% acc, however note that OOD (Out-of-Distributation) performance really sucks, like the model is trained on 1-4 digit addition, but if eval on 5 digit numbers, the performance drop significantly.
Prompt-Tuning Hands-On
So how do we use a good out-of-box LLM model to solve these tasks without pre-training-finetuning? A simple solution might be build a translator to map from task “token space” to the token space of GPT, for example:
Translator Design
A similar idea to this is BLIP-2: https://arxiv.org/abs/2301.12597 Such design is actually complicated, imagine the translator needs to map to a very large embedding space of GPT model, which itself may inevitably contain entire knowledge of GPT, this will likely make the “translator” to be complicated encoder which also requires large amount of data to train, which goes against our purpose.
Soft-Prompt v.s. Hard-Prompt
One natural question is whether we should optimize for hard prompt (just tokens) or soft prompts. Ideally hard prompts are desirable cuz they are more aligned with LLM training objective and less prone to overfit. One example is AutoPrompt: https://arxiv.org/abs/2010.15980 which uses gradient guided search. Some of its searched result candidates are funny, below is relation extraction prompts found by AutoPrompt:
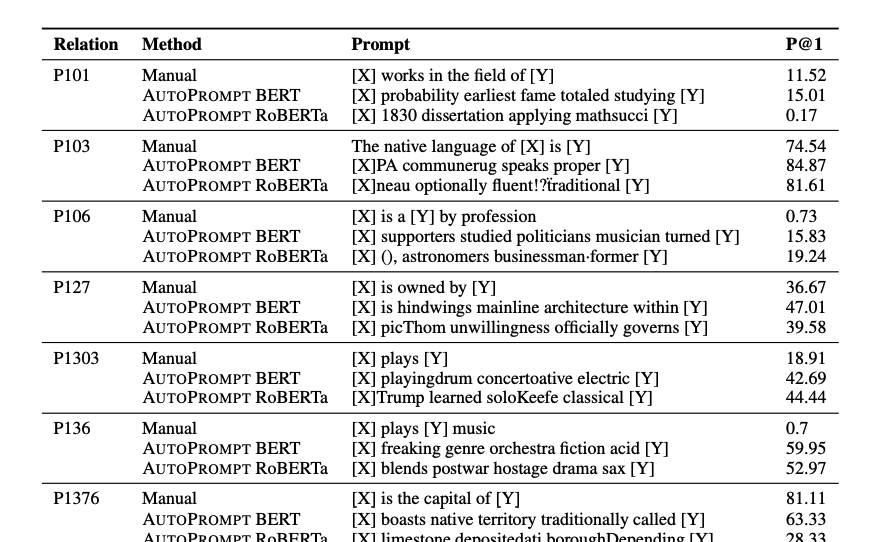
The lesson learned from AutoPrompt is that hard prompt search doesn’t turn out to eliminate overfitting problem, the resulted prompts are neither really legible nor sensible to humans, at the cost of a more complicated search algorithm. Our suspicion is that both hard and soft prompt search are likely to fall into the same estimator, with soft prompt tuning being much easier to implement and test. The drawback of soft prompt is feeding additional embeddings to the model which might change it’s original interface, but that’s usually not a concern in ML world. So in this study we merely focus on soft prompt tuning.
Prefix-Tuning 101
So how can we use only obtain “partial” knowledge of GPT to adapt it to our downstream tasks? Prefix-tuning https://arxiv.org/abs/2101.00190 is an excellent example of cheapest possible design, it adds
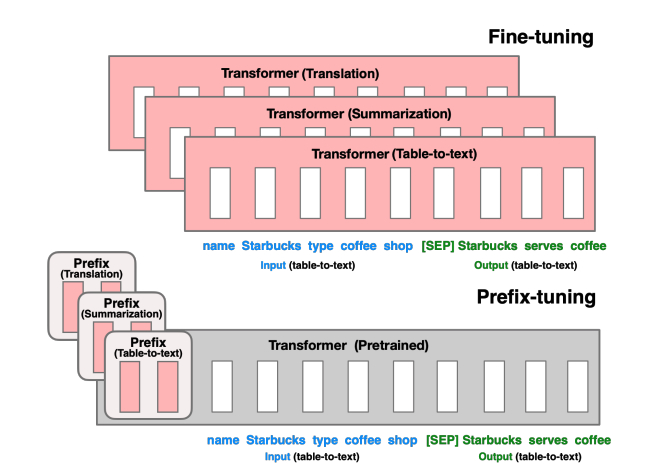
Prefix Tuning
It prepends soft-prompts (embeddings) to original prompt and use gradient information of the prefix only to finetune the prefix embeddings. Here we implemented a simple prefix tuning method, it has a hybrid of random initialized prefix + human provided trigger tokens as inspired by https://arxiv.org/pdf/2302.11521.pdf. Turns out it actually works! Rebasing on original NanoGPT2 code, with just a few lines of added, we’re able to successfully fine-tune NanoGPT2 to adapt to our tasks, results of arithmetic are shown below:
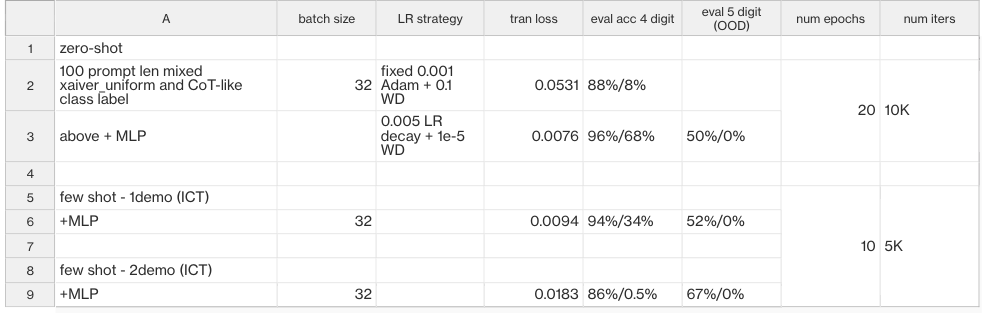
With the same dataset that we used to train a transformer from scratch, we obtain okay-ish performance, obviously it cannot beat a transformer that completely only trained for the task’s purpose, but it’s proved LLM can actually generalize to potentially any downstream cases like such. We have a few observations from the above experiments:
- Adding few shot does not help, likely it’s b/c of inferior of nanoGPT2 as super weak LLM, with bigger LLMs it’s likely to improve much. Nonetheless, prompt-tuning is built for zero-shot only.
- Adding MLP layers for the prefix embeddings does improve performance
- Both random init and init from trigger token are necessary to improve performance.
- OOD prediction still sucks, prompt-tuning is likely to overfit on specific data distribution is given dataset is small, however such case is likely in human prompt-engineering as well. In human engineered prompt, one can only have good faith that LLM can actually “understand” that’s what we intend them to do and generalize, while prompt tuning is more specific to ask LLM to perform specific tasks, like adding 2 numbers together.
One additional funny observation is that we found nearest neighbors of obtain soft prompts (embeddings) and decode them into actual words, and they make no sense at all as a prompt, this is similar observation from hard prompt search (token space only): https://arxiv.org/abs/2010.15980 https://arxiv.org/pdf/2211.01910.pdf you just cannot reason how LLM actually performances inference, soft-prompt strategy like prefix tuning completely operates at embedding space and has no meaningful correlation with human engineered prompts.
Results on letter reverse and last letter concat are shown below:
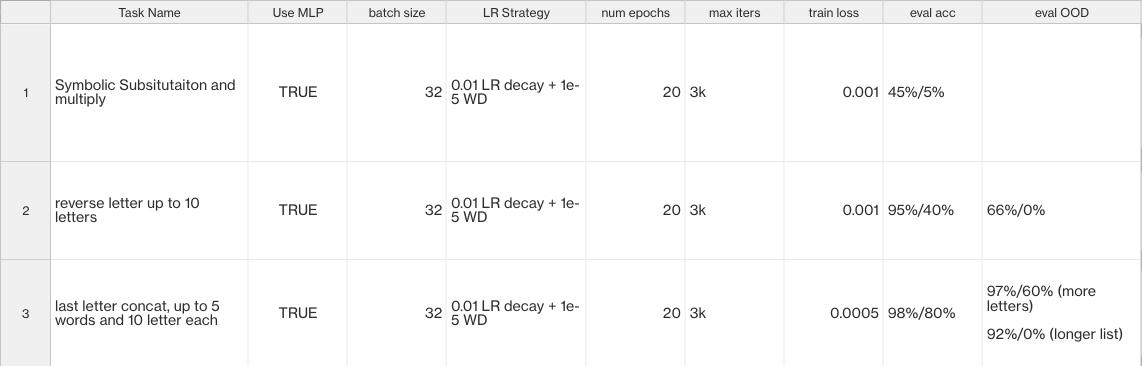
The result is also decent. The result is prolly inferior to GPT3 with proper human prompt engineering, but with nanoGPT2 is def a step change, no way you can prompt such a weak LLM to compute reverse letter for you.
Note that symbolic task particular sucks, it is just hard to convey the “series”, “iterative” and “recursive” such concept to LLM purely thru prompt tuning, this will rely on advancement of LLM itself. For instance, as of 2023 chatGPT can handle arithmetic sequence pretty well thru very simple natural language instructions. So great advancement of LLM can also partially eliminate the needs of prompt-tuning, since just simple human prompt engineering is well enough to provide perfect acc.
What’s Next
Try Prompt-Tuning on more recent LLMs like LLAMA
Evaluate Prompt-Tuning on more non-typical NLP benchmarks — the benchmarks we’re aiming for should be problems that are solvable for LLM but hard to convey as natural language prompts, such as symbolic manipulations, word scrambling, converting unstructured to structured data or vice versa. We believe prompt tuning has the potential to achieve superior performance on such kind of tasks.

One thought on “LLM Studies (Part 3) – Prompt Tuning”