This a series of posts discussing technical details of LLM. As early practitioner of LLM, I would like to share a series of technical reports to the community as my work progresses.
For LLM pre-training, I want to focus on “feasibility” in this blog post. Summarizing the training recipe from published papers is easy, in fact the process looks incredible simple — this resulted in the perception in the community that the bottleneck of pre-training is only hardware resources: as if with abundant GPUs LLM training can be well-democratized — well in principle I don’t disagree with this point, but I would like to point out a few details that poses great challenges for LLM practitioners, even if they already obtain the training resource.
As hundreds or even thousands of players in the ML community nowadays are eager to try out pre-training, the community also needs to be pay attention to the immense power cost of pre-training, often in the scale of Mega-Watts. I hope the data points shared in this post can also raise awareness of carbon footprint of pre-training, and be responsible for it.
Data
Public Dataset
The training data come from scraping the web, the notable ones are Google C4 (750GB), CommonCrawl (1TB). Here I roughly summarized disclosed dataset compositions from SOTA LLM papers:
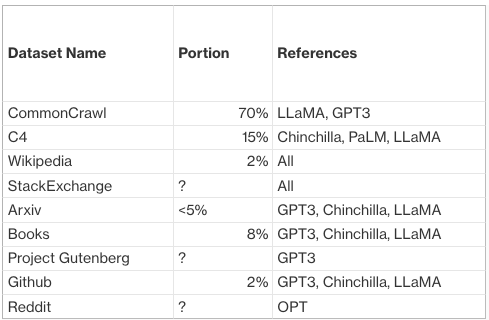
Note this list is for illustrative purpose and by no means exhaustive nor up-to-date, those are just the datasets that I have personally used. With the boom of LLM I have no doubt there will be more higher quality pre-training corpus released in future.
Private Dataset
WebText (Openai) 40GB. Note WebText used in GPT3 which is essentially 3 -years ago, GPT4 as of 2023 should have a much more powerful dataset.
Inifiniset (Google), a mishmash of C4, google’s code, wikipedia. Also human worker collected 6000 dialogs
Feasibility
Dataset curation is one of THE most heavy-lifting job in LLM pre-training. Curating pre-training dataset involves 2 time-consuming steps:
- Cleaning up public data source, such as CC, Wikipedia, Reddit, Github etc. there’re a lot of papers talking about detailed process on how to cleanup such for language modeling
- Composition of different data to increase diversity, GPT3/ChinChilla/PaLM/LLaMA each has their secret recipe on how to compose different portions of public dataset. The goal is to increase diversity without introducing bias & toxicity. Ideally the composition should be optimized/guided by eval results, in reality thru my experience, this process is quite messy with a lot of legacy pipelines, trivial knowledges, and copy-pasting other team/research facility’s results. I surmise OpenAI has a much more matured data pipeline to build/explore pre-training corpus.
If you wouldn’t bother curating your own data, there’s also an off-the-shelf public dataset: The Pile. The Pile by itself is not considered as a high quality pre-training corpus (tons of duplicates). There’re a few latest efforts trying to repro high quality corpus of SOTA LLMs, the most notable one is RedPajama (https://www.together.xyz/blog/redpajama), which tries to repro LLAMA’s dataset.
Modeling
Architecture
Prenorm transformers + specialized weight init + [optional] sparse attentions
12~96 layers, 1000 ~ 10000 d_model, <=2048 seq len, Adam, multi-step LR warmup + decay
Scaling hit a wall at 500B params, there is no LLMs beyond 500B up to Jan 2023
[Update on Jul 2023] rumor says GPT4 consists of 8 160B ensemble, so it’s considered reaching 1 trillion milestone, maybe?
Feasibility
- Model Parallelism Decision Chart
Typically a pre-training job ranges from 32 – 2000 GPUs, here I present my own design chart on parallelism selection, more in-depth parallelism design can be found in Megatron
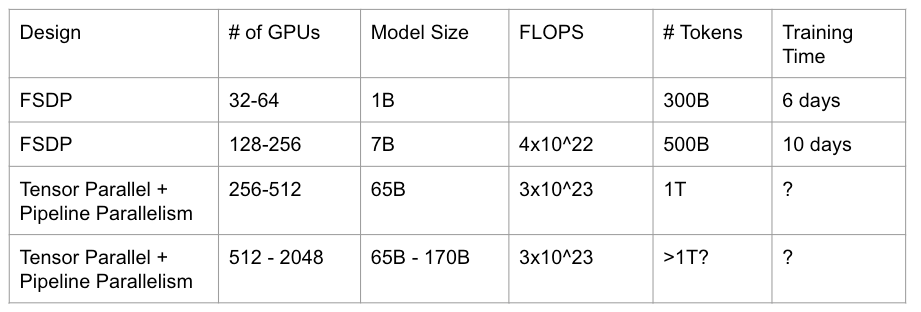
2. Training Settings
We summarize the training settings from published LLM works, in our practice the settings are well aligned with my own observations.

Evaluation
First of all, you need to use a held-out eval set of training data to perform eval on-the-fly to monitor overfitting. From my own experience, it requires quite some effort to conduct hyper-parameter tuning at the initial training curve to make sure the held-out eval loss is in accordance with train loss.
Here we summarize a few common LLM evaluation benchmarks in the table below:
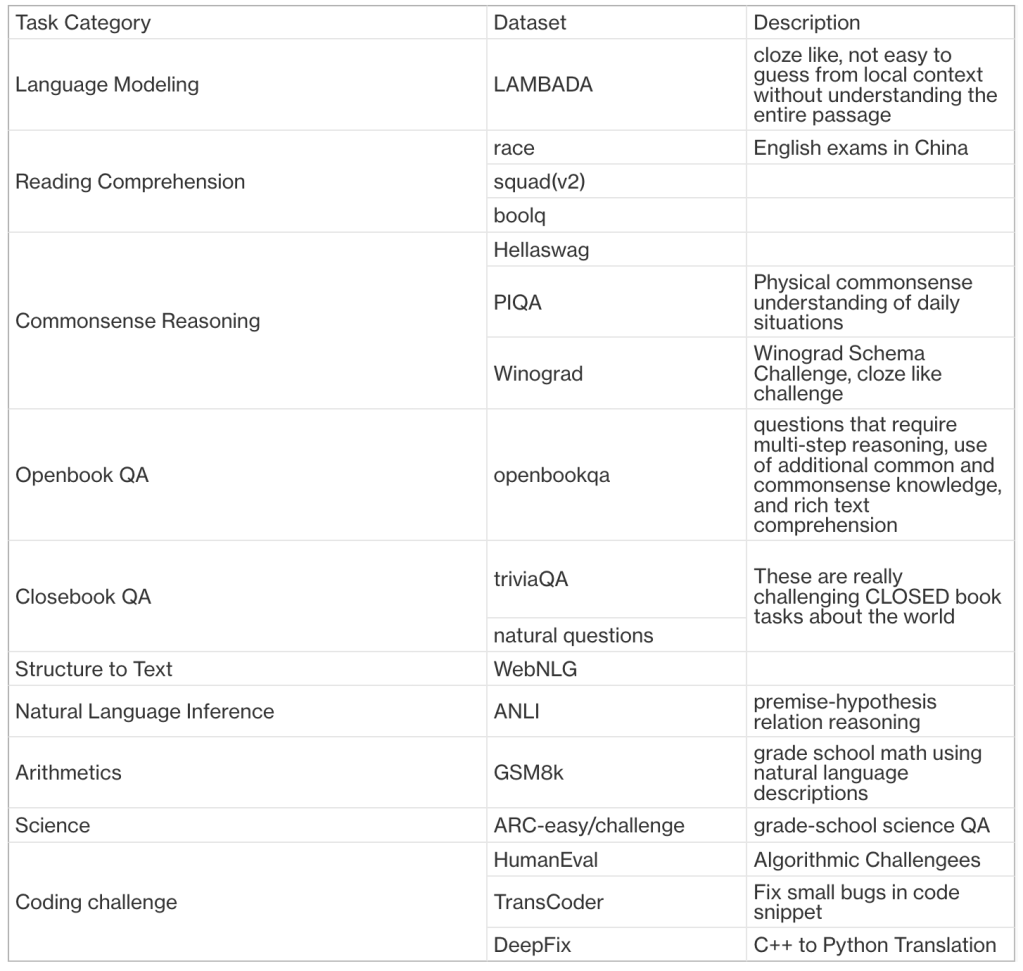
Feasibility
Conducting eval on public dataset is relatively easy, there are already OSS projects like https://github.com/EleutherAI/lm-evaluation-harness that have collected a sufficient set of eval tasks.
Eval on perplexity is always easy, eval on generation tasks is hard. In general most of the public datasets are perplexity based. For hard-generation tasks like coding, eval does not look so easy. For example, when evaluating on pass@k metric for coding tasks, it matters how you sample, also the cost skyrocketed when you need to sample that many output from LLM, for example, decoding speed per-GPU for 65B+ LLM is <10 tokens per second unless applying very sophisticated CUDA level optimizations.
Scaling Law
Here we use the scaling law definition from Chinchilla. Given a fixed compute budget (FLOPS), scaling law points out the training loss pareto-front optimal (loss frontier) for data size D and model size N (Efficient Frontier). The loss frontier is depicted below:
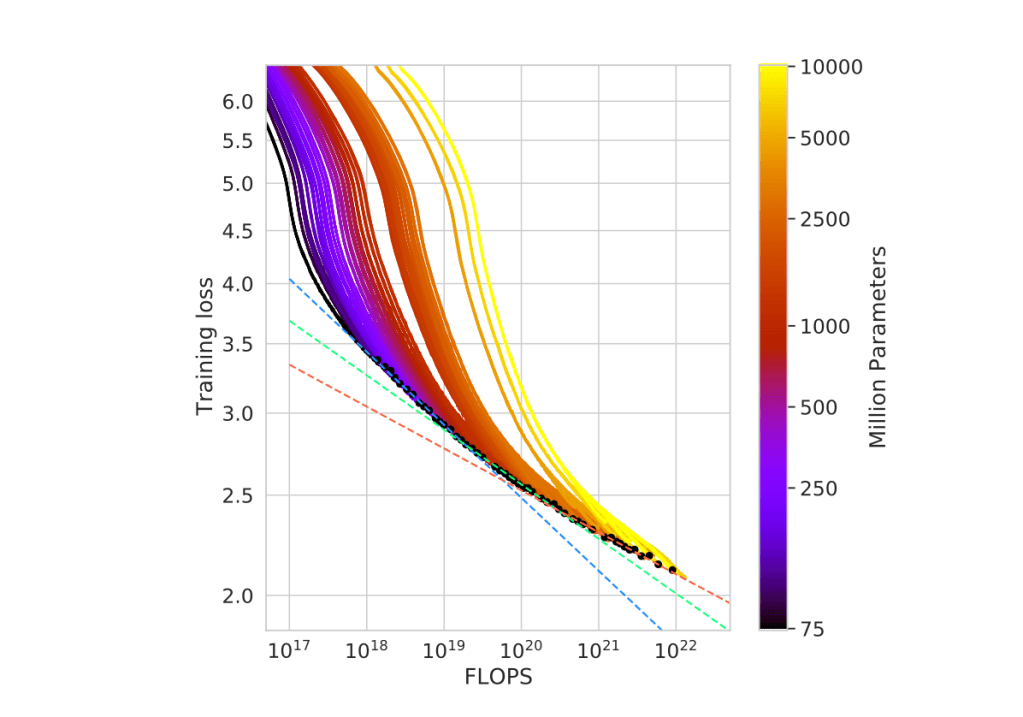
The curvature of the frontier is getting close to log-linear of FLOPS above 1B model size scale. This is an important observation that leads to the power law assumption of Efficient-Frontier:
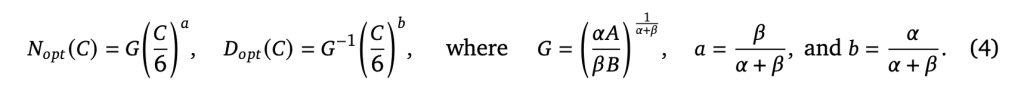
From Chinchilla’s results, a ~ b, so somewhat suggesting an equal scaling (linear relationship) between D and N, for example, Chinchilla estimated 8B data tokens for a 400M model, 200B tokens for 10B model. This is quite different from the original scaling law paper (https://arxiv.org/pdf/2001.08361.pdf) where a~0.7, b~0.27, suggesting a power law of N=D^2.5. As shown in the chart below, Chinchilla predicted a much higher data portion than what’s actually used by GPT3.
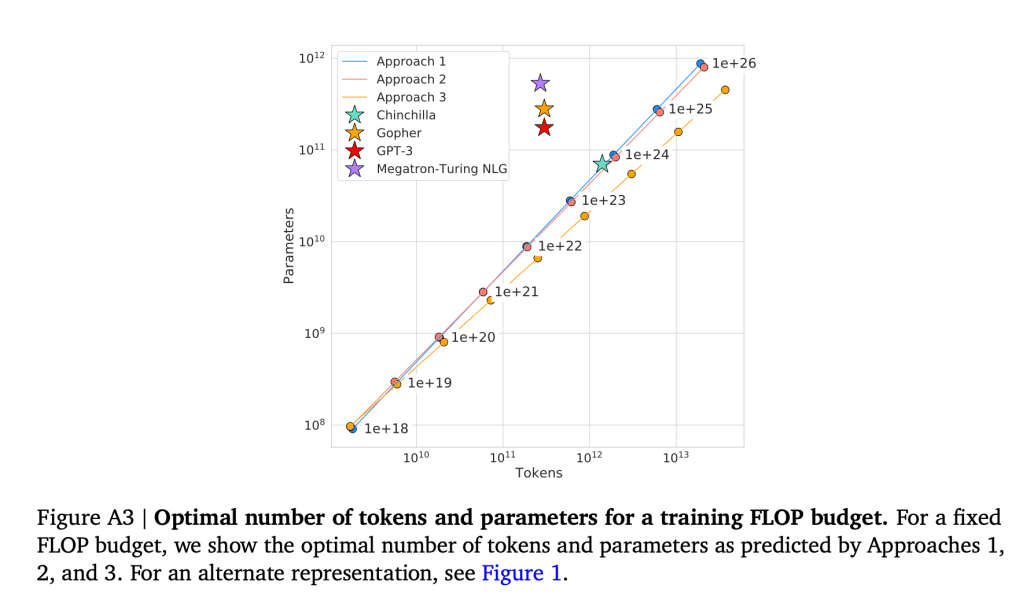
Newer gen LLMs such as LLaMA clearly favors Chinchilla, and put much of the focus on dataset curation. I personally really like Chinchilla’s prediction: such linear scaling between data and model size is not only observed in LLM but also in RecSys where I heavily work on, showing a strong proof.
Feasibility
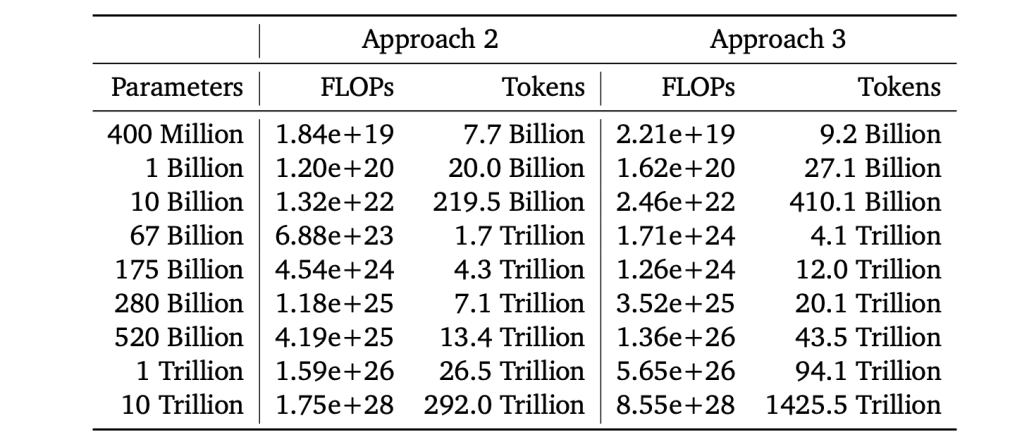
Scaling law is one of THE most important, fundamental discoveries of AI Research. All the pre-training experiments will be guided by scaling law. For example, the predicted training budget, training tokens and model size from chinchilla is as such:
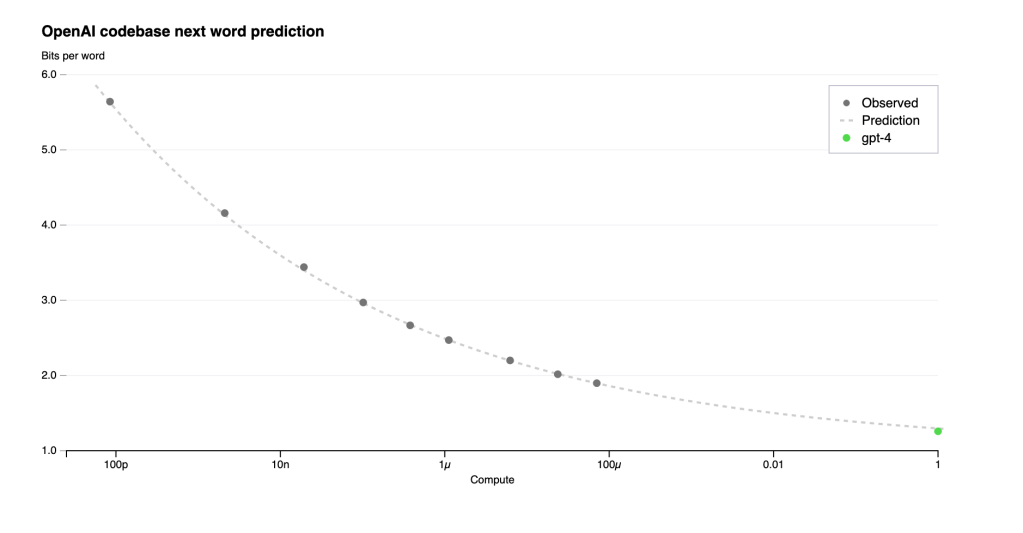
During pre-training, there will be many many hyper-parameters to explore, i.e. architecture details (heads, layers, d_model), dataset preprocess, dataset compositions, optimizer parameters etc. The exploration cost can go out of control with such a search space. A super interesting point brought up in openai’s blog is about “predictable scaling”. My own guess is that the exploration of a certain baseline is also guided by prediction: starting from a “lightweight” baseline, for example, 100M model, the training loss of 100B model can be extrapolated using a few datapoints at 100M scale (maybe plus historical datapoints as well). I really like the mindset of responsible LLM exploration with carbon footprint considerations. While AI Research is for human good, we need to be serious about wasted power (often in scale of MW by big tech companies) used in exploration.
Luckily, majority of the AI community don’t need to worry about this. There are already well-setup baselines, including pre-trained artifact with commercial license (see MPT, LLaMA, GPT-J). So most LLM practitioners don’t need any pre-training exploration at all, just starting from an existing open-source checkpoint and do your fine-tuning works. As of 2023 LLaMA model series is the hottest shit ever in OSS AI community. We see the release of LLaMA greatly accelerates LLM finetuning research, a great thumb-up for Meta holding ground the open-source mindset as more LLM big-players tend to close source.
That’s IT? Pre-training? Easy is it?
Say Imma LLM-enthusiast, sounds easy to do your own pre-training right? Big no, I can for-see 3 huge roadblocks to democratize LLM pretraining:
- Data Pipeline: none of the big players, Google/Facebook/Openai have released their data processing pipeline, nor will they have any motivation to do it in future. Such data pipeline is so tied to their core infrastructures (also likely to be a mess of legacy shit piles). There are OSS efforts like RedPajama trying to repro LLaMA’s dataset and release it to use out-of-box. Nonetheless it will be a time-consuming and human-in-the-loop intense effort for any organization.
- Training stability: as model size goes up to 60B, loss divergence, even explosion starts to occur. There is no panacea for such training stability issues, batch size/learning rate/gradient clipping all need to be fine-tuned, and often times it depends on luck by doing re-training, as model is trained with trillion of tokens, which usually last weeks, the re-training cost also grow wild. Until 2023 I don’t see any success example on auto-diagnosis → handling of such type of failures, the debugging is always human intense and frustrating.
Say you already have a perfect recipe shared on OSS (kudos to HuggingFace!), are you good to go? There are still rock hard infrastructure barriers you need to conquer, the ones I have observed are:
- Upholding GPU efficiency when using >1000 gpus, advanced model parallelism is required. One of the leading work/library on this is Megatron: https://github.com/NVIDIA/Megatron-LM
- Strong checkpointing infra is required, save/loading TB scale model in parallel by hundreds of nodes.
I don’t personally have experience using cloud HPC solutions such as AWS Ultra-cluster, so I don’t have a first hand knowledge on how “democratized” of running large HPC jobs nowadays. But overall managing a large HPC cluster is no joke, 2-3 dedicated tier-1 MLOps teams are required to my estimate.
Appendix
Chronicles of LLM Research
The zero-shot performance leap from GPT2-GPT3 is really the dawn of AGI dream coming true. 2022-2023 is where we see the boom of LLM applications boom after teh fundamental research break-thru.

Selected Eval Task Examples
Sentence Entailment
Sentence 1:A smaller proportion of Yugoslavia’s Italians were settled in Slovenia(at the 1991 national census, some 3000 inhabitants of Slovenia declaredthemselves as ethnic Italians).
Sentence 2:Slovenia has 3,000 inhabitants.
Output: not_entailment
NLI
Hypothesis: The St. Louis Cardinals have always won.
Premise:yeah well losing is i mean i’m i’m originally from Saint Louis andSaint Louis Cardinals when they were there were uh a mostly a losing teambut
Output: contradiction
——————————————————————————————————-
Hypothesis:Valence was helping
Premise:Valence the void-brain, Valence the virtuous valet. Why couldn’tthe figger choose his own portion of titanic anatomy to shaft? Did he think he was helping?
output: contradiction
——————————————————————————————————-
Question:effect
Premise: Political violence broke out in the nation.
Choice 1:Many citizens relocated to the capitol.
Choice 2:Many citizens took refuge in other territories.
output: true
——————————————————————————————————-
Squad-Like
Question:What does increased oxygen concentrations in the patient’s lungsdisplace?
Context:Hyperbaric (high-pressure) medicine uses special oxygen chambersto increase the partial pressure of O 2 around the patient and, when needed,the medical staff. Carbon monoxide poisoning, gas gangrene, and decompressionsickness (the ’bends’) are sometimes treated using these devices. IncreasedO 2 concentration in the lungs helps to displace carbon monoxide from theheme group of hemoglobin. Oxygen gas is poisonous to the anaerobic bacteriathat cause gas gangrene, so increasing its partial pressure helps kill them.Decompression sickness occurs in divers who decompress too quickly aftera dive, resulting in bubbles of inert gas, mostly nitrogen and helium, formingin their blood. Increasing the pressure of O 2 as soon as possible is partof the treatment
Output: carbon monoxide
PIQA
Corrected Answer: Using a brush, brush on sealant onto wood until it is fully saturated withthe sealant.
Context: How to apply sealant to wood.
——————————————————————————————————-
Context: My body cast a shadow over the grass because
Answer: the sun was rising.
OpenBook QA
Context→Organisms require energy in order to do what?
Correct Answer→mature and develop.
Incorrect Answer→rest soundly.
Incorrect Answer→absorb light.
Incorrect Answer→take in nutrients.
——————————————————————————————————-
Context→Question: George wants to warm his hands quickly by rubbing them. Whichskin surface will produce the most heat?
Answer:
Correct Answer→dry palms
Incorrect Answer→wet palms
Incorrect Answer→palms covered with oil
Incorrect Answer→palms covered with lotion
——————————————————————————————————-
Context→lull is to trust as
Correct Answer→cajole is to compliance
Incorrect Answer→balk is to fortitude
Incorrect Answer→betray is to loyalty
Incorrect Answer→hinder is to destination
Incorrect Answer→soothe is to passion
——————————————————————————————————-
ARC Commonsense
Context→Question: Which factor will most likely cause a person to develop a fever?
Answer:
Correct Answer→a bacterial population in the bloodstream
Incorrect Answer→a leg muscle relaxing after exercise
Incorrect Answer→several viral particles on the skin
Incorrect Answer→carbohydrates being digested in the stomach
Trivia QA
Q: ‘Nude Descending A Staircase’ is perhaps the most famous painting bywhich 20th century artist?
A: MARCEL DUCHAMP
Generation
Write an outline for an essay about John von Neumann and his contributions tocomputing:I. Introduction, his life and background
A: His early life
This is the research for an essay:
==={description of research}===
Write a high school essay on these topics:
===
Here’s a message to me:
—{email}—
Here are some bullet points for a reply:
—{message}—
Write a detailed reply
Write a creative ad for the following product to run on Facebook aimed at parents:
Product: {product description}
Rewrite
Rephrase this for me: “I can’t seem to find out how to work this darn thing.”Alternate phrasing: “
Covert my resume into a profile overview.{resume}Profile overview:
write rap lyrics on the topics mentioned in this news article:
—-{article}—-
Extract
Extract all course titles from the table below:
| Title | Lecturer | Room |
| Calculus 101 | Smith | Hall B |
| Art History | Paz | Hall A
Extract all place names from the article below:
{news article}
GSM8K
Tracy used a piece of wire 4 feet long to support tomato plants in the garden. The wire was cut into pieces 6 inches long. How many pieces did she obtain?
A: The wire was 4 feet long. This means it was 4 * 12 = 48 inches long. It was cut into pieces 6 inches long. This means she obtained 48 / 6 = 8 pieces. The answer is 8.
Q: Tom’s ship can travel at 10 miles per hour. He is sailing from 1 to 4 PM. He then travels back at a rate of 6 mph. How long does it take him to get back?
A: He travels at 10 mph from 1 to 4 PM. This means he travels 3 hours. 3 hours at 10 mph means he travels 3 * 10 = 30 miles. He then travels back at 6 mph. This means he travels 6 miles per hour. He has to travel 30 miles, so it takes him 30 / 6 = 5 hours. The answer is 5
Q: Stephen placed an online order for groceries. His final bill came to $40.00. Because this was through a delivery vendor, they tacked on a 25% fee to his final total and charged him $3.00 in delivery fees. Stephen also added a $4.00 tip. After the extra fees, what was the final price of Stephen’s groceries?
A: Stephen’s bill was $40.00. The delivery vendor added 25% to the bill. This means the bill was increased by 25% of $40.00. This is 0.25 * $40.00 = $10.00. The delivery fee was $3.00. The tip was $4.00. So the total bill was $40.00 + $10.00 + $3.00 + $4.00 = $57.00. The answer is 57
Q: There are four schools competing at a basketball tournament. Each school has sent a girls’ basketball team and a boys’ basketball team and each team has 5 players each. Each school has also sent a coach for each team. In total, how many people have all of the schools sent?
A: Each school has sent 2 teams, each with 5 players. This means each school has sent 2 * 5 = 10 players. Each school has also sent 2 coaches. This means each school has sent 10 + 2 = 12 people. There are 4 schools, so in total all of the schools have sent 4 * 12 = 48 people. The answer is 48
DROP (Discrete Reasoning Over the Content of Paragraphs)
Answer each question using information in the preceding passage.
Passage: In the city, the population was spread out with 12.0% under the ageof 18, 55.2% from 18 to 24, 15.3% from 25 to 44, 10.3% from 45 to 64, and 7.1%who were 65 years of age or older. The median age was 22 years. For every 100females, there were 160.7 males. For every 100 females age 18 and over, therewere 173.2 males.
Question: Which age group had the second most people?
Answer: [target completion: “25 to 44”]

One thought on “LLM Studies (Part 1) — Pre-training Feasibility”