What is “model productionization” and how is different from traditional software’s “productionization” process?
Revisit Traditional Software Development
Let’s look at 2 popular software platform architectures:
- Micro-Service Oriented Architecture
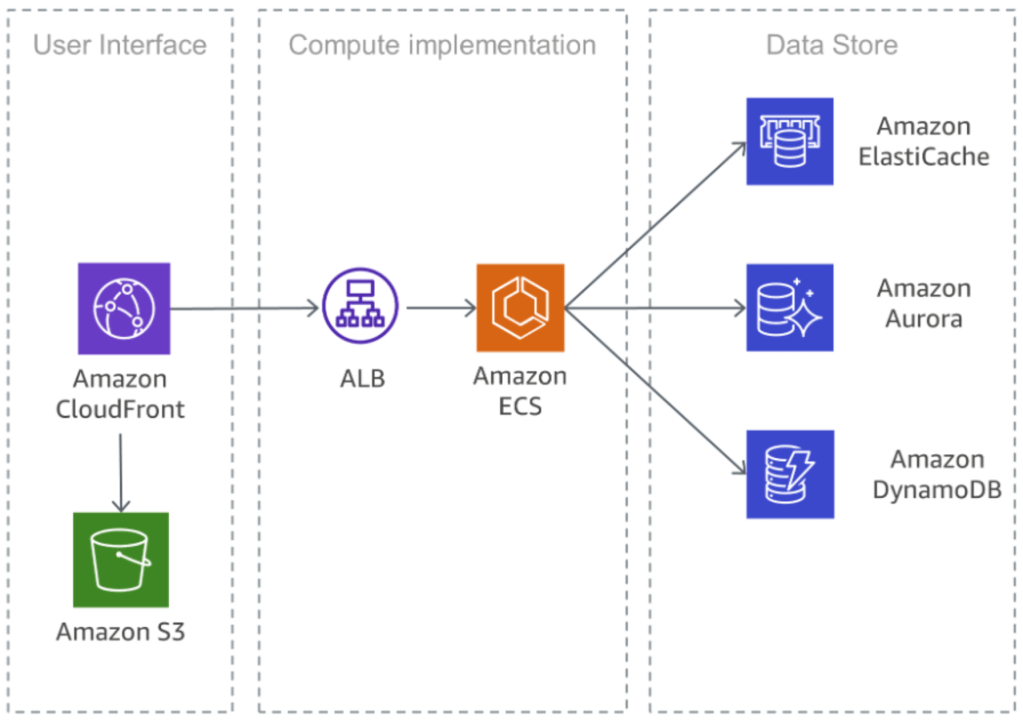
The principle is to split “monolithic” design into singular function “micro-services”. Each micro-service has simple, well defined input/output specs, and with good network infrastructures such design can scale to thousands of micro services. Such design has huge implications of the entire life-cyle of your software: you can retire/replace a micro-service almost hot-plug, a good solution architect can figure out 99% of business problem without digging into code; you can also define well-established operational standards (SLAs), assign domain experts to different services, build team/organizations based on your service design — it’s the most typical software paradigm used by majority of big/small companies nowadays.
2. Layered Architecture
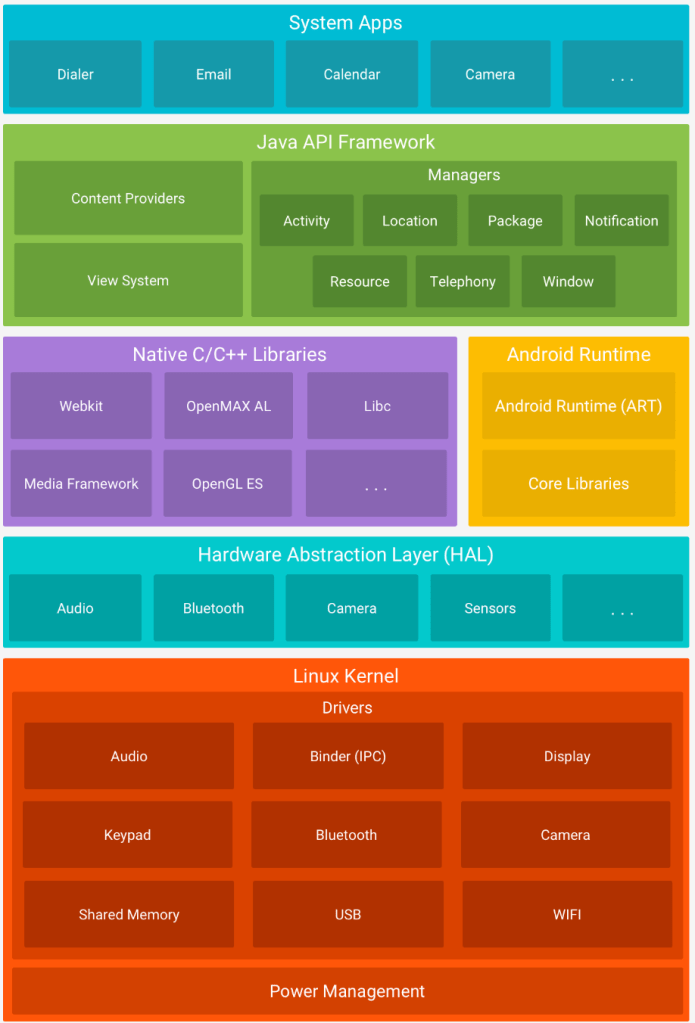
This is classic operating system design, layers of softwares pile up to digest the complexity of the system. Typically, a request/API call is assumed to pass down all the layers. Application owners will develop on “middleware” provided by upstream software publishers. The entire system can grow to extreme level of complexity: consisting of hundreds of millions of lines of code.
Layered design allow developers to “delegate” responsibility to experts that holds specific domain knowledges about a certain field, often very complicated, such as device drivers, kernel modules, GUI etc. The delegation mechanism is also coming out of the art of traditional software practices: the vendors’ libraries are usually reliable, inter-operable, and efficient. Tens millions of Android developers working on millions of apps every day; millions of developers collaborate worldwide on Linux Kernel — it is truly amazing how human beings can collaborate at such scale.
What About ML Development?
Thru the 2 examples we have observed the 2 key end-goals of software architectures: scalability and maintainability. Sadly, none of the above 2 is ever addressed seriously in nowadays’s Machine Learning platforms, today’s ML platform:
- No way to build a model with 100+ collaborators
- Immense cost to maintain a model after it’s been put online.
We’re still stone age in this business. To justify this claim, let’s look at how today’s ML development process has evolved from research to production:

The Polygon block, where the model building process, is really the bottleneck here. ML models, especially deep learning models, are known to be black-box magics: looking at the “model code”, you cannot reason much about it — even by the very first researcher who built it. Essentially the model code is a computation graph, meaning the boolean algebra we used to analyze software programs does not apply here, in other words, if you are a sophisticated programmer with sharp eyes to identify bugs in the code, you can’t help much anything here; if you have a static analysis tool for typical softwares, it won’t work here. To make it worse, building probing/explanatory tools on ML models is very hard, there is random nature in the model that ends up producing inconsistent signals: asking GPT2 same question twice it’ll give you different answers. So nowadays industry rely heavily on “E2E Testing” block to verify models assuming the signal is “stats sig” (statistically significant) — remember as models get large, this becomes very, very expensive and only a few tech companies with insane computation clusters and power can afford. So sry, large ML models are only the toy of a few big players like Google and Facebook. A 10 ppl start-up can build & run a software with altogether 1M+ line of code using Android API, or by integrating with AWS micro services, however, very unlikely they can afford to build/maintain a ML model with more than 1000+ lines of complexity.
So ppl would argue that why model building is important. Things like data, feature and publishing are already well structured as typical software systems, old dog old tricks — and models — well — only few of them are available on the market: ResNet, Transformers, BERT-variants, stable diffusions… and I swear the implementation of any of the above is no more than 200 lines of python code — for real. Tho I don’t have data points, it’s very likely that a single good software engineer or researcher can handle the entire model building of the largest ML model on earth in 2022 — I’m only referring to the “development” effort, where the engineer is already given a spec of what the model graph looks like, and start implementation. The exploratory work to know exactly why the model looks like this, however, is immense. So ideally, you only need to hire 1 single engineer for “modeling works”, provided you know exactly what that model should look like.
But is this really the case tho? Is it that ML development complexity all hides in data/features? Are we satisfied with the stagnant progress with model building? Absolutely not, if we only assume data is how we use to control the ML models, the cost of “Quality Assurance” (QA) simply cannot scale, imagine you will have to re-train and re-test a gigantic LLM, using thousands of GPU hours (still growing crazy) to test a small feature release — which is exactly what happened today. We need to build fundamental architecture paradigms to actually bake business logics into ML model and have them tested/QA-ed for customers. We are well aware of the statistical nature of the models and we do have metrics to verify stats-sig to give us confidence, however we need a solution to scale the development process to hundreds, or even thousands of engineers and still have it maintainable.
2 Possible Paradigms, Current and Future State
I here-upon provide 2 typical architectures in today’s industry. I’d like to note we’re by no means close to have as good as Android-like solutions for ML systems, it’s still stone age but maybe over another 1000 years progress:
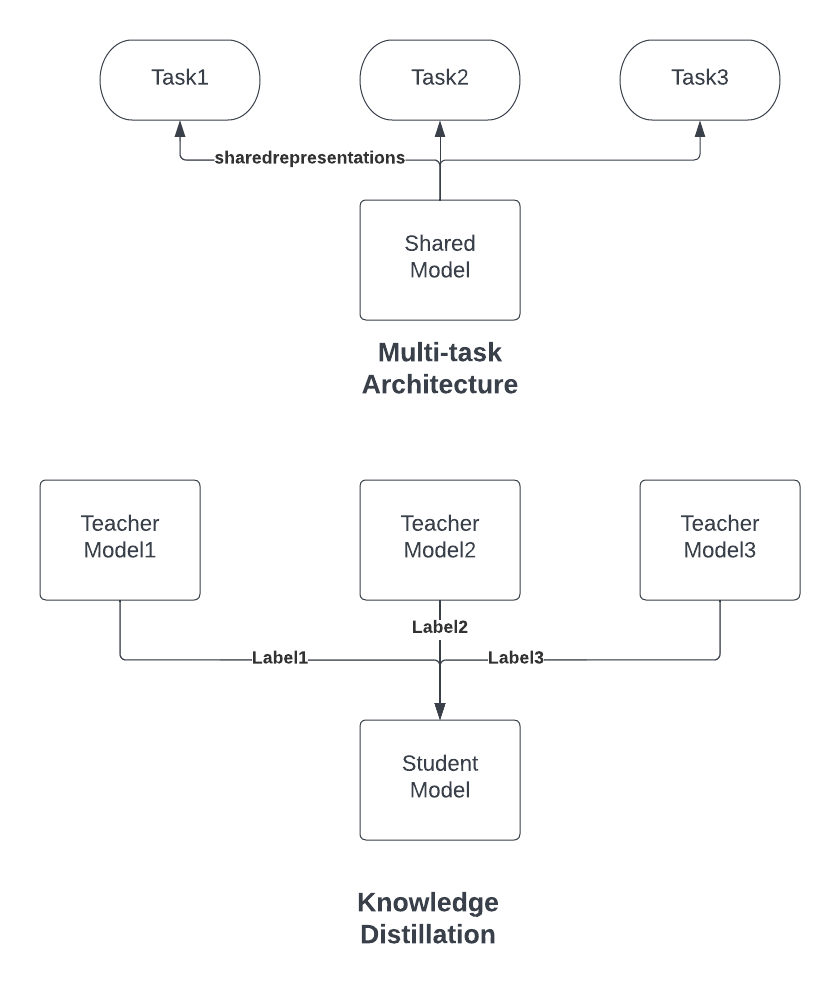
- In Multi-task architecture, the master model (shared) will be a much more powerful model “pre-trained” with humongous data volume that is assumed to be “universal”. The “universalness” is expressed by its shared representation, usually in the form of “embedding vectors” that are passed to downstream “task” units, where the task model will “fine-tune” itself based on its own case-specific, smaller dataset. Thru this way the task and shared models are “decoupled”, hence significantly reduce the cost of testing/rollout of individual tasks. Currently this design is widely used in NLP/CV industries solutions. The drawback is obvious the cost of the shared model, and very very often, because of constraints of deep neural networks, you still cannot bypass the cost of re-training the shared model, which degenerates to monolith solution.
- In Knowledge distillation architecture, we instead manipulate the “dataset”. This is very typical in nowadays’s RecSys industry practices. By decoupling “label generation” process, we’re often able to drastically reduce the size of the “main” model. A good example of this is TinyBERT where the large LLMs are able to shrink as much as 100x that can fit on edge devices like mobile phones. The real problem of this approach is scalability — you cannot easily control the main model behavior with labels, in today’s KD algorithms, using too many labels will end up having them compete with each other and producing unreliable predictions. Also, again, very often times you cannot easily shrink the model size with distillation, which still end up training a large monolith model.
The path to scale ML development still has long way to go. Neither of the 2 paradigms above can bake business logics safely into ML models. There are a few reasons why these problems are not treated seriously:
- The ML community is still research-ie, and to some extent, exclusionary; it is always cool to build new models and fancy algorithms, whilst production works are not “cool”.
- ML development still happens in one or two artisan’s workshops, very few companies has legitimate business reason to scale their ML workforce; very few scenarios can ML actually drive huge business value.
This is really an under-invested area where it will be interesting to see progress in the next few years in both academia and industry.
